[翻译] Automatic deobfuscation of virtualized binaries with LLVM
文章出处:https://blog.thalium.re/posts/misc/llvm-powered-devirtualization/internship-report.pdf
介绍
国际混淆 C 语言代码大赛(International Obfuscated C Code Contest)创立于四十年前。其灵感源自一段故意编写得极其晦涩、远超一般“糟糕编程”的代码——“这不仅仅是糟糕的代码,作者简直是故意要把它写得这么糟!”[30]。在过去四十年中,软件混淆技术逐渐发展成为版权保护和网络安全中的关键手段。
以 C 语言为代表的编译型语言在执行前会被编译成机器码。这种机器码对于人类而言极其难以理解。长期以来,这种复杂性被认为已足以防止他人窥探程序内容。
然而,随着反汇编器和二进制分析工具的兴起,人们可以高效地分析二进制文件,机器码已不再足以阻止分析活动,这迫使人们寻求更强的保护措施。
为了防止二进制被分析,出现了许多保护策略,包括硬件级保护、反调试策略以及软件混淆。本报告将聚焦于混淆技术,即在不改变程序行为的前提下,使其更难被理解的技术。这类技术常被用于版权保护,或隐藏恶意意图。
混淆程序本身就被设计为难以分析,因此必须借助专门的分析工具——反混淆器(deobfuscator)。只有理解了混淆后的代码,才能在其基础上添加新功能或实现互操作性。此外,反混淆器在恶意软件分析中也扮演着重要角色。
在网络安全,尤其是恶意软件分析中,混淆技术至关重要。大量恶意软件都采用混淆来阻碍人工分析并规避自动检测。广泛认可的 MITRE ATT&CK 框架中,甚至为“混淆文件或信息”设立了专门的技术类别 [12]。
恶意软件混淆技术可以非常简单,例如使用 RC4 或 Base64 对字符串进行混淆 [22];也可以非常复杂,例如在 BackdoorDiplomacy [7] 和 KillDisk [20] 等恶意软件中使用的 虚拟化混淆器 VMProtect。
面对复杂的混淆器,必须使用专门的反混淆器才能理解恶意软件的行为。在本次实习中,我们的重点是对虚拟化后的二进制进行反混淆。尽管已有多种自动反混淆技术可用于此类二进制,但我们想探索这些策略在现实世界中混淆程序上的适用性。因此,我们将特别关注可扩展性和性能表现。我们计划使用当前最先进的反混淆策略构建一个原型工具,并借助 LLVM 来证明其性能优势。
在构建该工具之前,我们将首先介绍二进制分析与反混淆领域。我们将从通用的二进制分析策略与局限性谈起,随后讨论混淆技术,并揭示其与二进制分析弱点之间的关联。最后,我们将探讨当前的反混淆方法,了解其原理,并评估其效果。
在综述现有研究的基础上,我们将明确本工具的目标范围,并简要介绍 LLVM。接着,我们将分享一次手动反混淆的实验过程,并深入介绍工具本身的设计决策、实验结果与局限性。
PartⅠ现状综述
1 二进制分析
二进制分析旨在从可执行的二进制文件中提取语义。Rice定理[40],这是可计算性理论中的一个基本结果,指出:“所有非平凡的程序语义属性都是不可判定的”。不幸的是,在二进制分析的情况下,Rice定理阻止了任何通用算法的存在。相反,二进制分析工具必须依赖启发式方法,这些方法要么无法覆盖全部情况,要么偶尔存在不准确,导致覆盖率与正确性之间的权衡。理解这种权衡对于更好地理解二进制分析中所采用的策略非常重要。
1.1 初步分析
1.1.1 指令恢复
二进制分析的一个重要初步步骤是恢复指令。由于机器码难以理解和操作,二进制分析工具首先尝试对其进行反汇编,也就是恢复程序的汇编代码。图1展示了程序的不同表现形式:图1a包含源代码,图1c包含Amd64汇编指令,图1d包含完整ELF二进制文件的十六进制转储。虽然单条指令的解码较为容易,但尝试反汇编整个程序时会遇到挑战。众多不同的指令集架构(ISA)进一步增加了反汇编的复杂性。例如,以广泛使用的Intel架构为例,其使用可变宽度编码并允许代码中混合数据,这带来了特定的挑战。Wartel等人证明,在x86二进制中区分数据和代码是一个不可判定的问题,因为该问题可以归约为著名的停机问题[55]。由于这一限制,必须使用启发式方法,这些方法不能保证正确性,但能提供近似结果。可使用不同策略,例如线性扫描以获得更好的覆盖率,或递归下降以获得更高的正确性[36]。

1.1.2 中间表示
中间表示(IR)是一个可选步骤,用于促进进一步的分析。许多二进制分析工具[38][32][17](以及混淆工具[46]和去混淆工具[18])都依赖于IR。IR是一种新的语言,在其上进行分析更为容易。这种新语言通常提供更多的抽象。例如,LLVM的IR[29]允许使用类型、变量以及带参数的函数调用。图1b包含了图1a中C代码对应的LLVM IR。将二进制文件提升为IR可能成为二进制分析工具的瓶颈,因此这一过程不应被轻视[24]。IR还允许重用底层逻辑,因为许多指令集架构(ISA)都可以被提升到同一个用于分析的IR上[16]。因此,IR是编写跨平台工具的基础。
1.1.3 构建控制流图
二进制分析工具构建的核心结构之一是控制流图。CFG 是程序控制流的表示,通常在函数级别构建。程序被划分为多个基本块(basic blocks),这些基本块之间通过条件跳转进行连接。在每个基本块中,所有指令都会按顺序连续执行。图 2 展示了一个计算 Collatz 猜想运行次数的函数对应的控制流图。
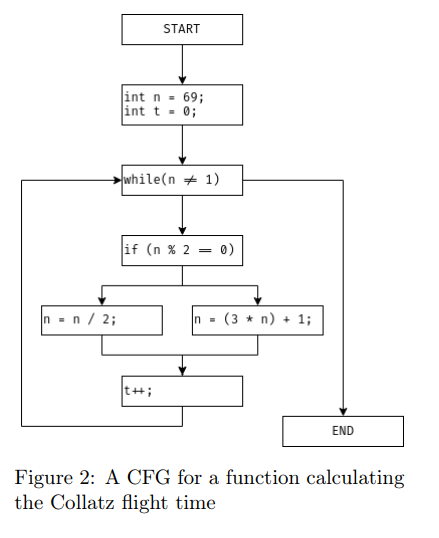
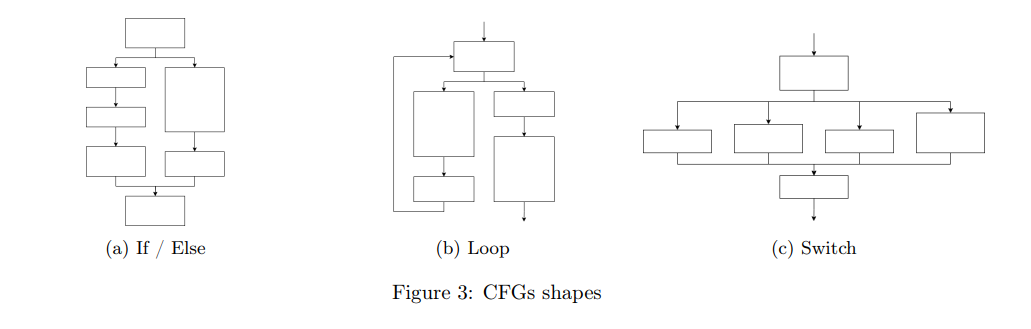
构建 CFG 并非易事。例如,在构建过程中,必须识别出跳转指令及其跳转目标,而这在存在间接跳转(indirect jumps)的情况下尤其困难。Dennis Andriesse 等人发现,CFG 的准确性与指令恢复的质量密切相关 [1]。为了构建 CFG,存在许多复杂策略,例如使用符号执行(symbolic execution) [48]。还有一些工具(如 Radare2 [38])依赖一套手工设计的复杂启发式规则 [36]。CFG 的一个重要特征是它的结构形状。分析人员可以通过 CFG 的形状快速识别程序中的不同控制流结构,如 if/else、while 或 switch。图 3 展示了一些典型的控制流结构示意图。
1.1.4 恢复函数边界
为了便于分析,能够识别并独立分析各个函数是十分重要的。虽然在某些二进制文件中可能包含函数的位置信息(例如 ELF 文件中的 eh_frame 段),但这种情况并不总是存在,在混淆过的二进制中更是少见。在没有显式标记函数起止位置的二进制中,识别函数边界是一项具有挑战性的任务。某些指令集架构(ISA)或中间表示(IR)甚至可能没有明确的函数调用指令 [16]。虽然编译器通常会在函数中添加易于识别的函数序言(prologue)和结尾(epilogue),但这也不是必然的,尤其是在启用了优化的情况下。函数边界恢复面临的一个特别困难是非返回函数(non-returning functions),它们可能与后续函数直接相连,难以分隔。此外,一些编译器优化技术也会加剧问题,例如:
- 函数内联(function inlining):将被调用函数的代码直接插入调用点,导致函数边界模糊;
- 尾调用优化(tail-call optimization):将尾部调用转换为跳转,也可能隐藏函数结束位置。
这些因素使得函数边界的恢复工作更加复杂和不确定 [36]。
1.2 污点分析
污点分析是一种用于分析程序中数据流动情况的策略,它可以以静态或动态的方式进行。在动态污点分析(Dynamic Taint Analysis)中,某些初始变量被标记为“污点”(tainted),在程序运行过程中,任何依赖于这些污点数据的变量也会被传播标记为污点。最终,所有被污染的数据都可以追溯到最初的污点变量,从而描绘出数据依赖关系的完整图谱。这种策略常用于确定程序中哪些部分依赖用户输入,因此在漏洞检测中具有重要作用。污点分析在二进制分析工具(如Angr [48])和去混淆工具(如Loki Attack [46])中均被广泛应用。
1.3 抽象解释
如前所述,大多数程序的语义属性是不可判定的。为了解决这一问题,Cousot 与 Cousot 于 1977 年提出了抽象解释(Abstract Interpretation)理论 [13]。抽象解释的核心思想是:对程序状态进行一种“紧致的过近似(tight over-approximation)”。为此,程序被提升到一个抽象域(abstract domain)中进行分析。一个简单的抽象域例子是区间抽象域(interval-based abstract domain),在该模型中,程序中的每个变量在执行路径上的任意时刻都被赋予一个值区间。随着程序执行的模拟,这些区间会不断传播和更新,直到达到一个不再变化的状态(不动点 / fix-point)。在实际的二进制分析中,往往需要使用更复杂的抽象域。例如,二进制分析工具 Angr [48] 引入并修改了 值集抽象域(Value-Set Abstract Domain),使其更适合于处理二进制程序。抽象解释在代码优化中也非常有用,典型用途包括死代码消除(Dead Code Elimination)和常量传播(Constant Propagation)。此外,抽象解释是许多二进制分析工具中的核心技术,例如BINSEC [17]和BinCAT [5]。
1.4 符号执行
符号执行是当前最有前景的二进制分析策略之一 [9]。它在分析程序时,引入了符号值(symbolic values),作为实际数据值的抽象替代。程序的状态因此可以表示为一组符号表达式。符号执行引擎会尝试探索尽可能多的执行路径,并在需要时为符号变量添加约束条件(例如,在遇到条件分支时)。最终,这些约束会交由 SMT(Satisfiability Modulo Theory,可满足性模理论)求解器处理,从而获取对程序变量行为的深入理解。
1.4.1 弱点与路径爆炸问题
符号执行并非完美无缺,其最显著的问题是计算开销巨大。当程序执行到分支处时,符号执行引擎会分叉并探索所有分支路径,每条路径对应一组独立的约束条件。这种路径数量指数级增长的情况被称为路径爆炸(Path Explosion)问题,在包含大量分支或循环的程序中尤为严重。当路径太多时,符号引擎可能陷入性能瓶颈,甚至内存耗尽。这还不是符号执行引擎的唯一限制。它们还可能受限于SMT求解器无法求解某些等式的问题。此外,符号执行引擎还需要访问代码以进行分析,而当程序与环境交互(如系统调用)时,这些代码并不总是可访问的(或者非常庞大)。符号执行引擎在建模内存方面也面临困难。内存模型的选择会极大地影响符号分析器的覆盖率 [9]。某些工具,例如 CUTE [47],仅支持指针的等值操作,而另一些工具,例如 KLEE [8],则使用数组理论对内存进行建模。
1.4.2 混合执行
一篇综述文章《Symbolic Execution for Software Testing: Three Decades Later》提出了解决路径爆炸的一种策略:混合执行(Concolic Execution) [9]。“混合” 即 “具体-符号混合执行(concrete + symbolic execution),是一种符号执行的替代方式,它在程序运行时同时进行具体执行。这种方式允许引擎在路径过多或程序与外部环境交互时回退至使用具体值执行。混合执行以牺牲一定的完整性为代价,换取更好的性能和更高的准确性。确实,虽然它可能只探索一条路径(导致完整性下降),但可以保证该路径一定是可达的,因为有一个具体值确实到达了该路径(提高了准确性)。如果没有这样的具体值,某些状态可能包含 SMT 求解器无法识别的不兼容约束。因此,混合执行被用于二进制分析工具 Angr [48] 中,用于寻找潜在的漏洞状态。
1.4.3 SMT 求解器
符号执行依赖的求解器是 SMT(可满足性模理论)求解器,最著名的是 Z3 [15],由 Microsoft 开发。Z3 功能强大,支持布尔与向量操作,非常适合用于二进制分析。尽管 Z3 在历史上非常流行,但它并不总是最优解。SMT COMP 是一年一度的 SMT 求解器竞赛,评估各类求解器的性能。在 2023 年的 SMT-COMP 中,Bitwuzla [34] 被评为 QF_Equality+Bitvec 赛道的最佳求解器,而 Z3 并未参与该赛道 [49]。因此,针对不同问题选择合适的 SMT 求解器非常关键。
1.5 二进制分析研究面临的挑战
二进制分析本身就是一个难题,而对其进行研究则更是难上加难。在学术界,研究二进制分析面临诸多问题。其中最大的挑战在于建立“真实基准”(ground truth)。实际上,许多二进制分析工具都是为特定应用场景而设计的,而用于测试这些工具的数据集则可能引入偏差,从而影响结果的客观性。分析结果在很大程度上取决于分析假设和所选用的二进制文件,不同选择可能导致显著差异。此外,系统化与结果可靠性的问题也进一步加剧了困难。即使是使用相同数据集的研究,也可能得出不同结论(通常是由于工具版本不同,或分析工具本身具有一定的随机性)。有些论文甚至会直接指出其他研究结果存在错误,比如:“一项最近的研究(无意中)夸大了线性扫描法(linear sweep)的准确性”[36]。
2 混淆
混淆是一种在不改变程序原始行为的前提下,使程序更难理解的技术。理想情况下,人们希望通过混淆构造一个完美的“虚拟黑盒”(virtual black box),使攻击者无法分析程序。然而,Barak 等人在 2001 年证明了这种完美混淆是不可实现的 [3]。因此,实际应用中的混淆目标是阻碍(而非彻底阻止)分析。
混淆可以在源代码级进行(例如:Tigress [10]),也可以作为编译流程中的一部分来执行(例如:Obfuscator-LLVM [25])。与原始未混淆的二进制文件相比,混淆后的二进制往往效率更低。混淆后的程序体积可能比原始程序大 1000 倍,运行速度也可能慢 50 倍 [46]。因此,通常不建议对整个程序进行混淆。如果将混淆限制在一些关键区域内,那么性能开销是可以接受的。比如,一个恶意软件作者可能只会混淆其加密逻辑或与命令与控制服务器通信的部分。
Loki 的作者 [46] 提供了一个非常具有代表性的实际案例,用于说明混淆的真实代价。他们对 Libdvdcss 中用于解密 DVD 密钥的函数进行了混淆。该函数只执行一次,是破解者的首要目标。他们发现该函数的执行时间从 2,952 纳秒增加到了 937,606 纳秒。尽管这是数量级上的巨大差异,但对于普通用户来说几乎是无法察觉的延迟,因此从保护知识产权的角度看,这是可以接受的成本 [46]。
2.1 混淆的评估
在他们关于混淆的开创性论文中,Collberg 等人 [11] 定义了评估混淆效果的四个重要指标:
- Potency(强度) 衡量程序复杂度的提升程度。如果某种转换使程序变得更复杂(更难理解),则该转换被认为是“强”的。这个定义本身就带有模糊性,但作者给出了一些例子,如:增加程序体积、增加分支谓词数量、增加函数参数数量等。
- Resiliency(抗逆性) 衡量某种转换对自动去混淆工具的抵抗能力。Potency 是为了迷惑人工分析人员,而 Resiliency 则是为了迷惑自动化二进制分析工具。
- Stealth(隐蔽性) 衡量混淆代码与原始程序整体的融合程度。换句话说,是衡量人工分析者在多大程度上能察觉到混淆部分。
- Cost(代价) 衡量这些转换对程序性能和体积的影响。
2.2 威胁建模
在对程序进行混淆之前,首先要明确威胁模型,并理解攻击者的能力。例如:攻击者是想完整理解程序的语义,还是仅仅想提取出某一部分有价值的信息(如加密密钥)?攻击者是否已经知道程序中的某些逻辑?攻击者是否知道目标混淆代码的位置?他们是否能够执行动态分析?这些问题的答案将直接决定应使用哪种混淆器,以及哪些部分需要重点保护。
2.3 简单代码变换
最简单的一种混淆方式是对程序应用大量简单的代码变换,以使其更难理解。虽然这些变换本身不一定具有较强的抗逆性,但它们常常作为其他高级混淆策略之后的附加步骤,用于进一步增强混淆效果。
- 死代码(Dead code):指的是那些在程序执行过程中无法被到达的代码。添加死代码可以增加攻击者需要分析的内容,其中还可能包含一些干扰项(red herrings)。在某些恶意可执行文件中,死代码的体积甚至远超实际代码,例如将恶意程序“埋藏”到一个著名库文件中。通过静态链接也可以实现添加死代码并扩大二进制体积。
- 无关代码(Irrelevant code):与死代码类似,无关代码是不会影响程序行为的额外代码。但不同于死代码,它在执行过程中确实会被运行,只是不会产生任何实际作用。
- 代码克隆(Code cloning):也是一种增加程序混乱度的策略。一个具有多个入口的基本块可以被克隆成多个内容相同但只有一个入口的基本块。
- 不透明谓词(Opaque predicates):在最简单的形式下,它们是用于分支的恒等条件表达式。这些表达式可以始终为真(PT)、始终为假(PF),或者根本无所谓真假(P?)——即两个分支实际上执行的是相同的代码。在多数情况下,这些谓词本身也会被混淆,使其不易被识破。
- 编译器优化(Compiler optimizations):也可被用于代码混淆。一些常见的优化手段包括:循环拆分、循环重排、函数拆分、函数重排、代码重叠、指令重叠等。
许多混淆器会利用现有编译器的优化过程进一步加深混淆程度 [46]。
2.4 混合布尔-算术表达式(MBA)
混合布尔-算术表达式(MBA)首次由 Zhou 等人于 2007 年提出 [58],指的是将算术运算符(如加法 +、减法 −、乘法 ×)与布尔运算符(如非 ¬、异或 ⊕、与 ∧、或 ∨)混合使用的表达式。这类表达式之所以难以分析和求解,主要原因在于这些运算符之间缺乏通用的代数规则(例如不具备分配律、结合律等),导致简化和推导过程非常复杂。混淆器通常通过用 MBA 表达式替换等价的算术表达式来引入混淆,例如:
$$
(x⊕y)+2×(x∧y)=x+y
$$
当遇到复杂的 MBA 表达式时,SMT 求解器往往无法对其进行有效简化或求解,这会迷惑分析人员或阻碍符号执行引擎的运行 [19]。
此外,经过编译器优化后,MBA 表达式会变得更加复杂和难以理解 [19]。
2.4.1 MBA 链式组合
MBA 通常通过用预先计算好的 MBA 模式替换代码中的特定模式来生成。这种替换使得简单的 MBA 容易被模式匹配识别,因而存在一定的脆弱性。一种解决方案是链式组合 MBA,即在复杂表达式中,先将子表达式替换为 MBA 表达式,然后对新生成的表达式重复此替换过程,进行多层嵌套。需要注意的是,如果对原始表达式不加优先处理,这种链式转换可能主要改变的是 MBA 部分,而不是原始表达式本身的结构 [46]。
2.5 控制流平坦化
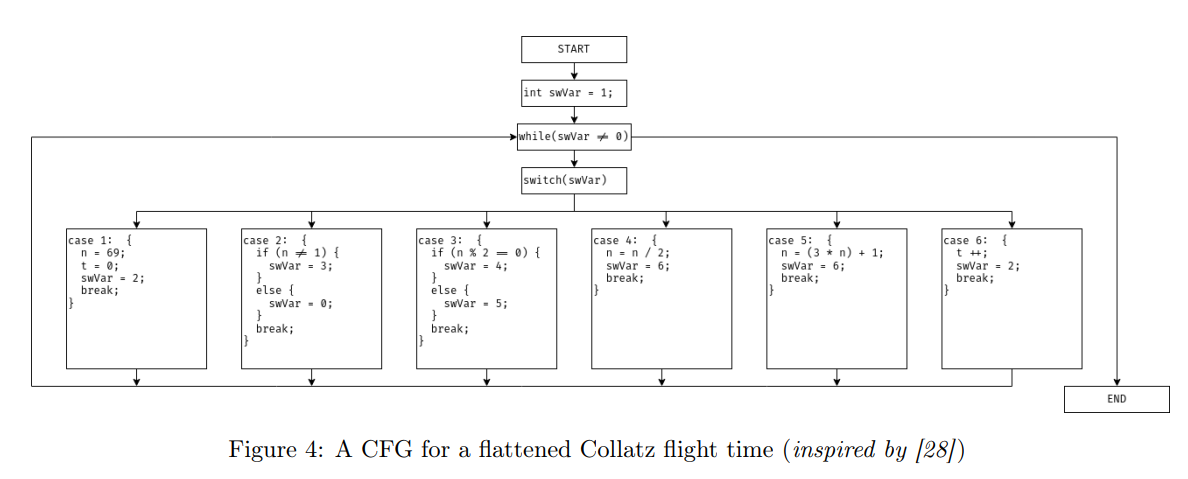
控制流平坦化(Control Flow Flattening)是一种旨在让控制流图(CFG)难以理解的混淆策略。它的实现方式是:将原本嵌套的所有基本块平铺(即彼此并列放置),并用一个调度器(dispatcher)对它们进行统一控制,例如通过一个 switch 语句。调度器本身则被包裹在一个循环结构中。程序内部的控制流通过一个变量来维持,该变量表示程序当前所处的状态。图 4 展示了一个 Collatz 程序在应用平坦化之后可能的 CFG 示例。在原始的控制流图(图 2)中,循环和分支结构非常容易识别(图 3 展示了一些典型的 CFG 结构),但在平坦化后的版本中,这种结构不再明显。在图 4 中,调度器是通过一个循环实现的,而变量 swVar 被用来表示程序当前的状态。需要注意的是,在实际的混淆二进制中,可能会使用多个变量来表示程序状态,进一步增加分析难度。
控制流平坦化会显著影响程序的执行性能:在一些实验性的例子中,程序运行速度降低最高可达 6 倍,而程序体积可能会增加最多 3 倍 [28]。
2.6 代码防篡改(Code Tamper Proofing)
在动态分析过程中,攻击者常通过修改二进制代码来获取程序的敏感信息。例如,通过跳过某个条件分支,攻击者能够获得程序关键部分的执行轨迹。代码防篡改技术旨在确保机器码未被非法修改,防止此类攻击。 一种常见技术是在 OLLVM 中应用的做法是:对机器码的各个代码段计算32位循环冗余校验码(CRC) [25]。 这些 CRC 校验结果被用来修改扁平化代码中的控制流结构,一旦检测到代码被篡改,程序行为将发生改变。这样一来,攻击者若想修改代码,不仅要修改目标代码本身,还必须同步修改包含该代码段的所有 CRC 值,大大增加了篡改难度。该技术介于混淆和反调试之间,但因分析混淆代码时很可能遇到,故将其归入本报告讨论范围。此外,这种代码防篡改实现会对控制流图(CFG)产生影响,进一步增加程序结构的复杂性和混淆程度。
2.7 虚拟化
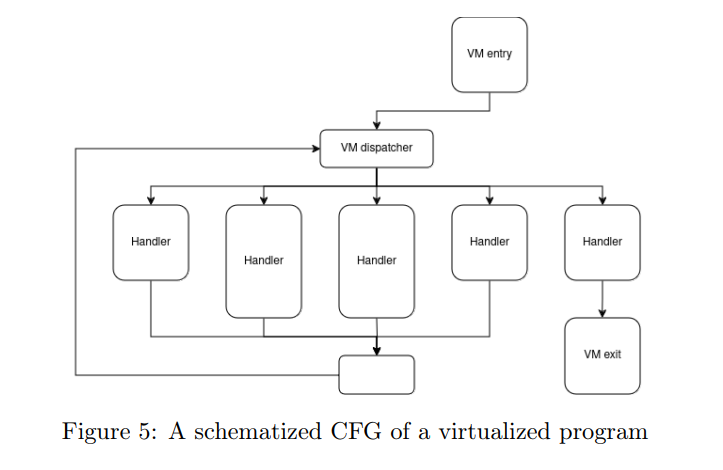
Kochberger 等人将虚拟化描述为“应用混淆中最强有力的技术之一”[27]。虚拟化是控制流扁平化的极端形式。在虚拟化二进制中,程序被编译成一个自定义的指令集(虚拟机指令集)。二进制文件中既包含编译好的字节码,也包含解释器。要理解虚拟化字节码,分析人员首先需要逆向解释器的行为。虚拟化二进制通常包含以下几个关键组件 [52]:
- 虚拟机入口/出口(VM entry/exit)
执行虚拟机与宿主环境之间的上下文切换,类似函数的序言和尾声。 - 虚拟机调度器(VM dispatcher)
负责执行取指(fetch)、解码(decode)、执行(execute)的循环。调度器在解码阶段最为脆弱,因为它是连接虚拟指令与底层逻辑的关键环节。 - 处理器表(Handler table)
存放自定义指令集的语义实现。
这些组件如图5所示:
2.7.1 虚拟机加固(Hardening Virtual Machines)
为了加强虚拟机,防止简单的模式匹配,虚拟化混淆器会从给定二进制构建指令集,将逻辑聚合成复杂的、特定于程序的单条指令。这些指令没有简单的助记符,给分析者理解带来极大困难。另一种加固方法是合并核心语义 [46]。通过向指令添加一个参数(称为“key”),可以在一条指令内选择不同的语义,例如:
$$
\begin{align}
f(x,y,k) &:= e_0(k)(x + y) + e_1(k)(x - y) \tag{1} \
e_i(i) &:= 1 \tag{2} \
\forall k \ne i,\quad e_i(k) &:= 0 \tag{3}
\end{align}
$$
在这个例子中,函数 f 是一个被等式(1)定义的函数,k是它的参数(key)。这个函数满足:
$$
f(x,y,0)=x+y\quad and\quad f(x, y, 1) = x - y
$$
2.7.2 性能
虚拟机的主要缺点是极高的性能开销,这是因为虚拟机需要动态解析和执行字节码。例如,在论文《Loki: Hardening Code Obfuscation Against Automated Attacks》中,作者发现使用虚拟化混淆的密码学原语可能会导致性能下降高达 15,000 倍 [46]。这种性能损失远远大于本文档中其他混淆策略,正是因为这种高昂的性能代价,虚拟机通常不会被嵌套使用。
2.8 总结
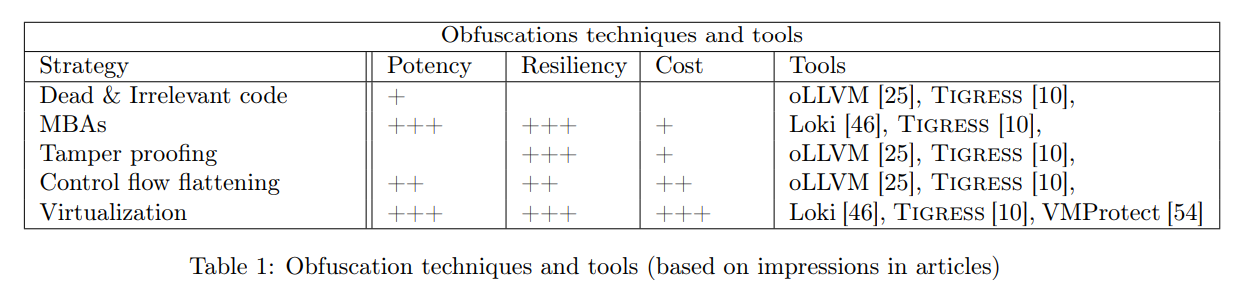
除了第 2.3、2.4、2.5、2.6 和 2.7 节中介绍的混淆策略之外,还有其他一些混淆策略存在。其中包括来自 Armadillo 的 nanomites [2](或其他类似的技术,它们依赖特定的操作系统特性来转换代码逻辑)以及字符串或代码段的加密。本报告中描述的混淆技术汇总可见于 表 1。需要注意的是,该表格是基于各篇文章中的主观印象创建的,而非基于实验数据或已有研究成果。
3 去混淆
去混淆(Deobfuscation)是指使被混淆的软件对人类和工具更易理解的过程。由于无法构建完美的混淆器,去混淆才成为可能。去混淆与混淆的过程就像“猫捉老鼠”的博弈,混淆器设计者与去混淆研究者之间不断相互对抗。有些去混淆器是为通用目的设计的,例如 VMAttack [53]、VMHunt [56];而另一些则是为特定混淆器量身定制的。一些研究人员甚至在发布混淆器的同时,一并发布相应的去混淆器(例如 Loki 和 Loki Attack [46])。二进制去混淆在很大程度上依赖于二进制分析工具。
3.1 定义简洁性
在进行去混淆工作时,有一个相当难以界定的概念,那就是“简洁性”(simplicity)。去混淆器的目标是逆转混淆器所施加的变换,因此它需要使程序变得更简单、更容易理解。我们在前文讨论“混淆强度(potency)”时就已经提到,与人类理解相关的定义往往非常复杂。当时我们借助一些例子和模糊的定义勉强说明了“potency”,但“简洁性”的问题依然存在。
我们以简化混合布尔-算术表达式(MBA)为案例进行说明。在论文 Defeating MBA-based Obfuscation 中,作者 [19] 讨论了“简洁性”的问题,并指出:算术表达式的最简形式并不一定是最易于理解的形式。有时候,因式分解后的表达式更加可读,如公式 (4),而其他时候,展开形式可能更容易理解,如公式 (5):
$$
\begin{align}
(1 + x)^{100} = 1 + 100x + \cdots + 100x^{99} + x^{100} \tag{4} \
(x - 1)(x + 1)(x - i)(x + i) = x^4 - 1 \tag{5} \
\end{align}
$$
同样的问题也出现在布尔表达式的简化中,乃至于程序整体简化的过程中。许多去混淆器和相关研究文章并未直接说明它们是如何定义“简洁性”的,而是仅仅关注能否还原出原始程序 [27]。
3.2 目标和约束
就像混淆需要考虑攻击者模型一样,理解去混淆器所面临的约束也同样重要。一个关键的问题是:去混淆器是应该完全自动化的呢,还是依赖人工分析呢?此外,还需要考虑的因素包括执行时间和计算资源。事实上,性能往往是一个显著的瓶颈。在 Kochberger 等人发表的系统性综述文章 [27] 中,去混淆器经常被描述为崩溃或耗尽内存。最后,任何先验知识(例如对混淆器的了解)都可能极大地促进去混淆过程的进行。
3.3 编译优化和LLVM
编译器优化是实现简单去混淆最有效的策略之一。在逆向恢复较弱混淆策略(例如死代码)时,有两个优化技术尤为突出:常量传播与常量折叠。
- 常量传播(Constant propagation):这是一种编译器优化策略,它将程序中使用的常量变量直接替换为其已知值。例如,在图 6a 中,变量
x被替换为了其值4。 - 常量折叠(Constant folding):这是一种编译器优化策略,用于计算仅包含常量的表达式的值。例如,在图 6b 中,变量
y的初始值从4 + 1简化为5。
通过反复迭代这些策略,可以不断发现新的常量(比如图中的变量 y),再将其传播,从而实现对程序的全面简化。随后可以进一步执行其他简单优化,如移除未使用变量等。
执行编译器优化的一个有效方法是使用与编译器相同的中间表示(IR)。正如我们在第 1.1.2 节中所看到的,IR 在二进制分析中非常有用,这里也是其另一项优势。例如,Saturn [21] 使用 LLVM IR 对二进制程序进行去混淆。该工具借助 LLVM IR 优化策略重建控制流图(CFG),并解开不透明谓词(opaque predicates)。该策略的最大挑战在于:需要将二进制代码提升为 LLVM IR。为此,Saturn 使用了 **Remill [39]**,再配合自定义逻辑和 Pass 实现这一过程。

3.4 控制流去平坦化
起初,控制流图去平坦化(CFG deflattening)看起来似乎是一项简单任务:找到调度器(dispatcher),然后将基本块(basic blocks)隔离并重新连接在一起。然而,控制流去平坦化的主要难点来自于编译器优化对程序结构的改变 [18]。实际上,编译器优化可能会对基本块进行拆分与合并,这使得还原原始基本块结构以及识别调度器变得非常困难。CaDeCFF 通过关注状态变量(state variable)而不是程序结构来解决这一挑战 [18]。该方法通过统计每个变量影响了多少个分支条件来识别状态变量——参与多个分支判断的变量更有可能是状态变量。
3.5 破解混合布尔算术表达式
SMT求解器通常无法简化或求解复杂的混合布尔算术(MBA)表达式。尤其是,尽管 Z3 有简化函数,但它无法简化或求解复杂的 MBA 表达式。
3.5.1 模式匹配
混淆器通常只使用少量的 MBA 表达式(例如 Tigress 仅有16种 [46])。如果能够识别出这些表达式,就可以将它们替换为等价的已知算术或布尔表达式。虽然这种策略高效,但在某些情况下存在局限性,包括面对组合的 MBA 表达式,或者不知道具体用了哪些 MBA(比如闭源或未知的混淆器)。
3.5.2 SSPAM 方法
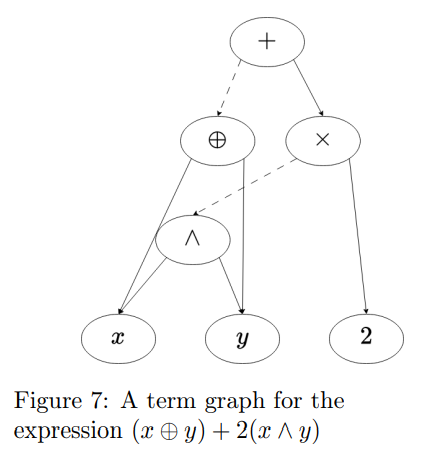
Eyrolles 等人在他们的工具 SSPAM [19] 中提出了一种不同的破解 MBA 的方法。首先将 MBA 表达式转换为一个术语图(term graph)(见图7)。然后对该树应用一系列转换,旨在减少树中节点数量以及 MBA 的交替程度。MBA 交替(MBA alternance)指的是连接算术表达式与布尔表达式的边的数量(图7中以虚线表示)。为了确定应用哪些转换,SSPAM 主要依赖模式匹配,但它也使用 Z3 构建等价的替代表达式,以最大化识别已知模式的可能性。
3.6 破解虚拟化
破解基于虚拟化的混淆并不是一项简单的任务。在其文章《Towards Static Analysis of Virtualization-Obfuscated Binaries》中,Kinder 指出许多传统的静态分析策略(包括抽象解释)并不能有效应对虚拟化 [26]。目前已有若干种策略被提出,这些策略的自动化程度和效果各不相同,本文仅涵盖其中的一部分。
3.6.1 抽象解释与虚拟程序计数器(VPC)
尽管“常规”的抽象解释无法破解虚拟化,但通过为解释器增加一个“维度”,可以构建一个更高效的虚拟机去混淆器。Kinder 发现,在抽象解释器中引入关于虚拟程序计数器(VPC)的信息后,他能够从一些虚拟化的示例程序中提取控制流图(CFG)[26]。通过提升抽象域,变量的抽象值不再仅依赖于程序位置,而是根据每一个(程序位置,VPC)对进行计算。
3.6.2 模式匹配
这种策略在针对特定混淆器的工具中尤其流行。这些工具首先基于对混淆器的了解识别出 handler(处理器)。一旦识别出 handler,就可以通过符号执行和污点分析提取其语义。例如,为了评估 Loki 混淆器而构建的去混淆器 LokiAttack 就采用了这种架构 [46]。如果可以进行动态分析,去混淆器还可以获取 handler 的执行轨迹。
3.6.3 程序合成
程序合成是应对虚拟化二进制代码的另一种方法。它在面对语法复杂度高但语义复杂度低的混淆代码时尤其有效。在程序合成中,handler 被视为黑盒,其语义通过观察输入和输出进行提取。只要知道预期操作及其输入输出行为,就可以在观察到 handler 的输入输出后“合成”其功能。Blazytko 等人率先通过其去混淆器 Synthia 实现了这一方法 [6]。
3.7 基于污点分析的策略
Yadegari 等人 [57] 采用启发式方法与污点分析相结合,从虚拟化二进制文件中重建控制流图(CFG)。他们在多个二进制文件和现实中的混淆器(包括 Themida [50]、VMProtect [54] 和 Tigress [10])上成功测试了这一策略。尽管他们并没有还原出去混淆后的二进制代码,但他们的方法和实验为本次实习工作的许多部分提供了重要的启发。
3.8 Triton
我们将讨论的最后一种策略是 Triton [43] 所采用的方法。Salwan 利用符号执行技术,成功自动去混淆了多个虚拟化二进制文件,其中包括 Tigress 挑战赛中的多个样本。该方法依赖动态污点分析来识别程序中哪些部分依赖于输入和输出。被污点标记的数据随后被用于部分重建原始的控制流图(CFG)。通过多条执行轨迹,去混淆器可以重建出原始的控制流。这些用于生成轨迹的输入由符号执行引擎提供,该引擎旨在最大化代码覆盖率。随后,这些轨迹被合并,并通过 LLVM 对生成的程序进行简化。
Part Ⅱ 实习工作
4 项目范围
在本次实习期间,我们专注于非常简单的函数,这些函数具有以下特点:
- 输入是一个整数
- 输出是一个整数
- 函数内部不包含任何函数调用
这种模型包括哈希函数,而哈希函数通常是被混淆的那类专有函数,正如 Jonathan Salwan 等人所讨论的那样 [43]。
我们所处理的程序遵循图 8 所示的模板:主函数读取一个输入,调用名为 SECRET 的函数,然后输出结果。
1 | |
对于我们的虚拟化混淆器,我们选择了 Tigress [10]。这一先进的混淆器允许用户选择要应用的混淆类型。在我们的项目中,我们只选择了应用虚拟化混淆。
Tigress 的作者还发布了若干挑战题 [51],这些挑战遵循图 8 所示的模板。该模板使得混淆后的程序可以依赖用户输入,同时又避免了在被混淆函数中处理函数调用和系统调用的需求。
5 LLVM IR 介绍
LLVM 最初被设计为一套用于构建“优秀编译器”的模块化工具。其中一个重要的特性就是它的中间表示(Intermediate Representation),通常被称为 LLVM IR,或简称 IR。
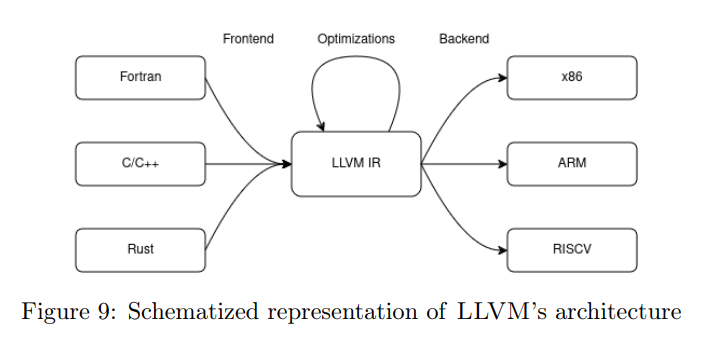
如图 9 所示,LLVM IR 位于前端与后端之间。它使得编译器开发者可以专注于编译器的某一特定部分。例如,编写 LLVM IR 优化无需与前端交互,而这些优化也能在不同前端下通用。
由于 LLVM 的各个工具彼此独立且拥有良定义的 API,开发者可以很方便地在不同项目中重用它们——这些项目不一定非得是编译器。在我们的项目中,我们就能够利用 LLVM 的优化能力,而无需处理前端或后端的细节。
5.1 LLVM IR的设计
LLVM IR 的规范载于 LangRef 中,且不一定向后兼容。我们决定采用 LLVM 版本 17。
5.1.1 摘要
与 Amd64 相比,LLVM IR 是一种相对较高级的语言。它具有以下几个特性:
- LLVM IR 拥有无限数量的寄存器,格式为
%<name> - 每个寄存器不是通过大小来区分,而是通过类型区分:
- 整数类型具有任意大小,涵盖从位宽 i1、常见的 i32 以及一些非常规的位宽如 i17。整数的有符号性不是在类型中指定,而是在需要的指令中定义。
- 指针类型是不透明的,统一标记为
ptr - 还有许多其他类型,包括浮点数、数组、向量和结构体等。
- 不需要调用约定(calling conventions),因为调用指令可以直接接受函数参数。
5.1.2 IR示例
我们来拆解一个简单的 LLVM 函数,该函数实现将输入乘以二。该函数的代码如下。
1 | |
在这个示例中,我们定义了一个名为 times2 的函数,它接受一个类型为 i32 的参数 a,并返回一个 i32 类型的值。在函数内部,我们使用 mul 指令将参数 a 与常量 2 相乘。我们指定结果的类型为 i32,操作数是寄存器 a 和常量 2。乘法的结果存储在寄存器 a2 中。最后,使用 ret 指令返回这个值。
5.1.3 静态单一赋值(SSA)
为了实现高效的优化,LLVM 的中间表示采用了静态单赋值形式(SSA)[7]。在 SSA 程序中,每个变量都是一个常量。与其写成 x = x + 1 并修改变量 x,不如创建一个新的常量 x2 并写成 x2 = x + 1。
5.1.4 Phi Node
如果我们尝试将一个更复杂的程序转换为 SSA 形式,可能会在表示循环和其他控制流图(CFG)结构时遇到困难。例如,让我们尝试将如下简单 C 语言循环转换为 LLVM IR。
1 | |
如果我们将这个程序直接翻译为 LLVM IR,会得到如下错误的程序。
1 | |
尽管这段代码是合法的 SSA 形式,但其语义并不正确。这个循环永远不会退出:每次迭代,它都将 0 加 1,然后将结果与 5 比较。我们实际上总是在对初始值进行+1,而我们真正想要的,是在每次迭代中对上一次迭代的结果进行+1。解决方案是使用 φ(phi)节点。φ 节点会根据控制流信息,为某个寄存器分配不同的值。下面展示了我们这个计数程序的一个正确 LLVM 实现版本。
1 | |
在这个新版本中,如果控制流是从 entry 跳转到 while,那么变量 i 的值为 0;如果控制流是从 while 跳转回 while(也就是循环继续),那么 i 的值则为 i2。换句话说,寄存器的值取决于它来自哪个前一个基本块。
φ(phi)节点是巧妙绕过 SSA 限制的一种方式。
5.1.5 LLVM 中的内存操作
绕过 SSA 限制的另一种方式是使用内存。在 LLVM 中,我们可以通过 alloca 指令在栈上分配空间,然后使用 load 和 store 指令来读取和修改所指向的数据。
下面展示了一个使用内存方式实现的计数程序的 LLVM 版本。
1 | |
在这个程序中,我们首先通过指令 alloca i32 分配一个指向整数的指针。接着,我们可以使用 store 指令来初始化这个值:store i32 0, ptr %i_ptr。这条指令的作用是将整数 0 存储到 %i_ptr 指向的位置。
在循环中,我们无需担心 LLVM 的 SSA 要求,因为我们并没有修改指针本身,而只是修改了它所指向的值。
5.2 常被误解的 GEP 指令
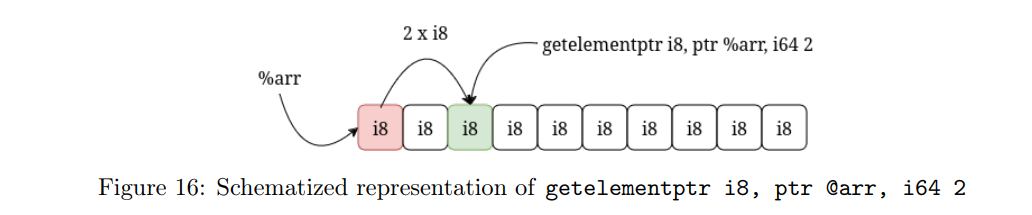
在 LLVM 中,指针运算是通过 getelementptr 指令来实现的,这条指令被称为 Get Element Pointer(GEP)。假设我们有一个全局的 10 字节数组,并希望访问其中的第三个字节(即偏移量为 2 的元素)。我们可以使用 GEP 指令来完成这一操作。下面展示了一个包含此用法的示例程序。
1 | |
让我们来看一下该示例中的 GEP 指令。在这条指令中:
- 我们指定了数组的类型:这里处理的是一个
i8类型的数组 - 我们指定了数组的初始地址:这里是全局变量
arr - 最后,我们指定了偏移量:在本例中我们想要访问第三个元素,因此偏移量是
2
图 16 展示了这条 GEP 指令的结构化视图。
现在,假设我们正在处理一个矩阵(即表格中的表格)。我们可以通过如下代码,访问第 2 行(偏移量为 1)和第 3 列(偏移量为 2)处的元素。
1 | |
第 3 行第 2 列的元素并不一定等于第 2 行第 3 列的元素,因此指令getelementptr [10 x i8], ptr %arr, i64 2, i64 1不会返回与访问第 2 行第 3 列相同的地址。
图 18 展示了这条 GEP 指令的结构化视图。
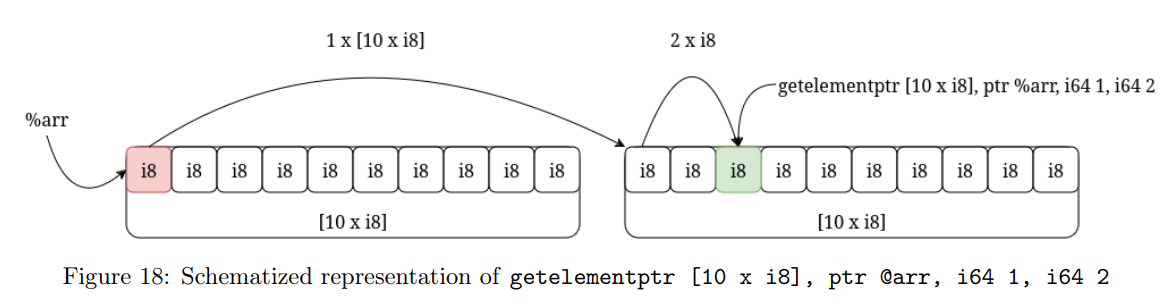
在背后,我们实际上是在计算:
$$
\begin{align}
1\ ×\ sizeof([10\ ×\ i8])\ +\ 2\ ×\ sizeof([10\ ×\ i8][1]) &= 1\ ×\ sizeof([10\ ×\ i8])\ +\ 2\ ×\ sizeof([1\ ×\ i8])\
&= 1\ ×\ 10\ ×\ sizeof(i8)\ +\ 2\ ×\ sizeof(i8)\
&= 12\ ×\ sizeof(i8)
\end{align}
$$
值得注意的是,这正好对应了 LLVM 在使用 -O3 优化时生成的代码。原始的 getelementptr 指令会被优化为:getelementptr i8, ptr %arr, i64 12。
我们知道,GEP 指令中的类型表示的是数组中元素的类型。但我们也可以在 GEP 指令中指定指针的完整类型,这需要在 GEP 指令开头添加一个偏移量,且该偏移量的值为零。如下展示了这个新的程序。
1 | |
在这种情况下,我们计算如下:
$$
\begin{align}
0\ ×\ sizeof(10\ ×\ [10\ ×\ i8])\ +\ 1\ ×\ sizeof(10\ ×\ [10\ ×\ i8][0])\ +\ 2\ ×\ sizeof([10\ ×\ 10\ ×\ i8][0][1])
&= 0\ ×\ 10\ ×\ 10\ ×\ sizeof(i8)\ +\ 1\ ×\ 10\ ×\ sizeof(i8)\ +\ 2\ ×\ sizeof(i8)\
&= 12\ ×\ sizeof(i8)
\end{align}
$$
这次同样是$12\ ×\ sizeof(i8)$。
5.2.1 LLVM中的结构体
LLVM 也允许我们使用关键字 type 来创建结构体。例如,%struct.Pair = type { i32, i32 }。在接下来的示例中,我们将使用 packed struct 来简化计算。 所谓 packed struct,就是在结构体不进行字节对齐的填充操作(默认情况下,字段通常按 4 字节对齐)。在如下代码中,如果结构体 Inner 不是 packed,其大小将是 48 字节,而不是字段长度的 45 字节。在 LLVM 中,packed struct 用如下方式表示:
1 | |
在 C 语言中,我们可以通过字段名直接访问结构体的成员,如上述代码中的third_inner函数所示。但在 LLVM 中,结构体的字段是没有名字的,因此我们需要使用 GEP 指令来访问这些字段。
通过使用 GEP 指针,我们可以访问结构体中的字段,在这里,“偏移量”对应字段的编号。让我们来拆解如下示例。
1 | |
在使用结构体时,GEP 指令用于获取结构体中特定的字段。例如,Inner 结构体是 Struct 的第二个字段,因此它可以通过偏移量 1 访问(索引仍然从 0 开始)。类似地,字段 arr2 是 Inner 的第三个字段,因此可以通过偏移量 2 访问。
在使用 -O3 优化级别后计算出的字节偏移量:getelementptr i8, ptr @obj, i32 49。
6 初步分析
在第一部分,我们尝试理解通过虚拟化实现的混淆是什么样子的。与现有先进技术相比,这里更多是一个技术性的实操演示。
6.1 人工去混淆
在深入自动化去混淆工具之前,了解另一种去混淆方法是很重要的:手动去混淆。这个实验将帮助我们判断是否真的需要自动化工具,同时也能让我们熟悉 Tigress 混淆器以及它生成的混淆代码类型。
作为案例研究,我们选择手动去混淆 Tigress 挑战赛中的 challenge0-1 [51]。这个示例是一个典型的二进制文件,包含一个简单的虚拟机,没有额外的混淆。由于这些挑战程序是随机生成的,我们不应期望去混淆后能识别出某个著名算法。
将该二进制加载到 IDA 后,我们注意到 IDA 在解析调度器中的间接跳转时遇到了困难。如第 1.1.3 节所述,间接跳转对静态分析是一个挑战。图 22 展示了 IDA 中混淆函数的整体视图。蓝色块表示虚拟机调度器(VM dispatcher)。正如第 2.7 节所解释,调度器是各个处理器(handler)的父块,因此应该拥有许多子块(虚拟机通常有多个 handler)。然而,在我们的示例中,IDA 无法识别出任何 handler。
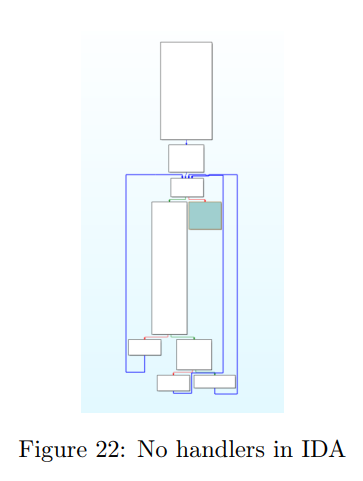
通过手动将 handler 添加到函数中,我们能够构建一个相对更准确的控制流图(图 23)。不过,调度器(图 23 中红色标记)仍未与 handler 相连。尽管我们找到了跳转表和所有 handler,但它们的格式不够标准,IDA 无法自动将它们关联起来。
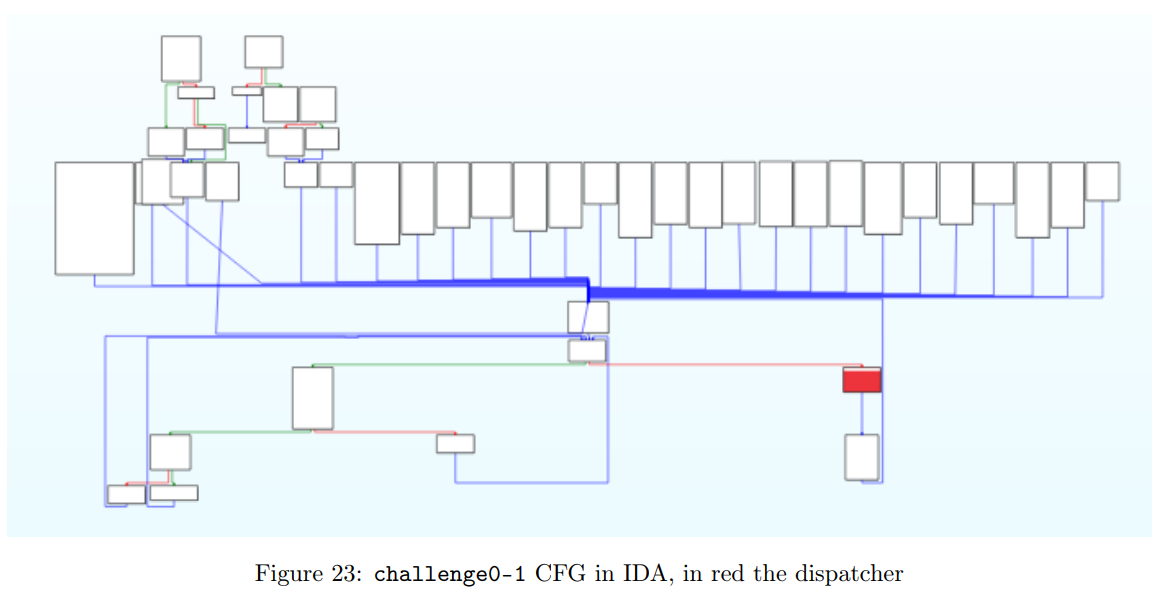
尽管缺少了一些边,但有了这个控制流图(CFG),我们现在可以尝试对该函数进行去混淆。策略如下:定位跳转表和虚拟指令,去混淆每个处理器(handler),然后编写脚本对虚拟化程序进行反编译。
如果查看一个 handler(见清单 24a),我们会注意到虚拟机操作的是一个由 s_p 指向的虚拟栈。大多数 handler 通过从栈中取出参数,执行操作,再将结果存回栈中来工作。
控制流则由一个虚拟程序计数器(Virtual Program Counter,简称 VPC,变量名为 i_p)管理,这个计数器在大多数 handler 中都会递增(见清单 24a)。该程序计数器用作偏移量,从混淆指令数组中取出指令码。然后通过二分查找,在“跳转表”中匹配每条指令码对应的 handler(见图 24b)。
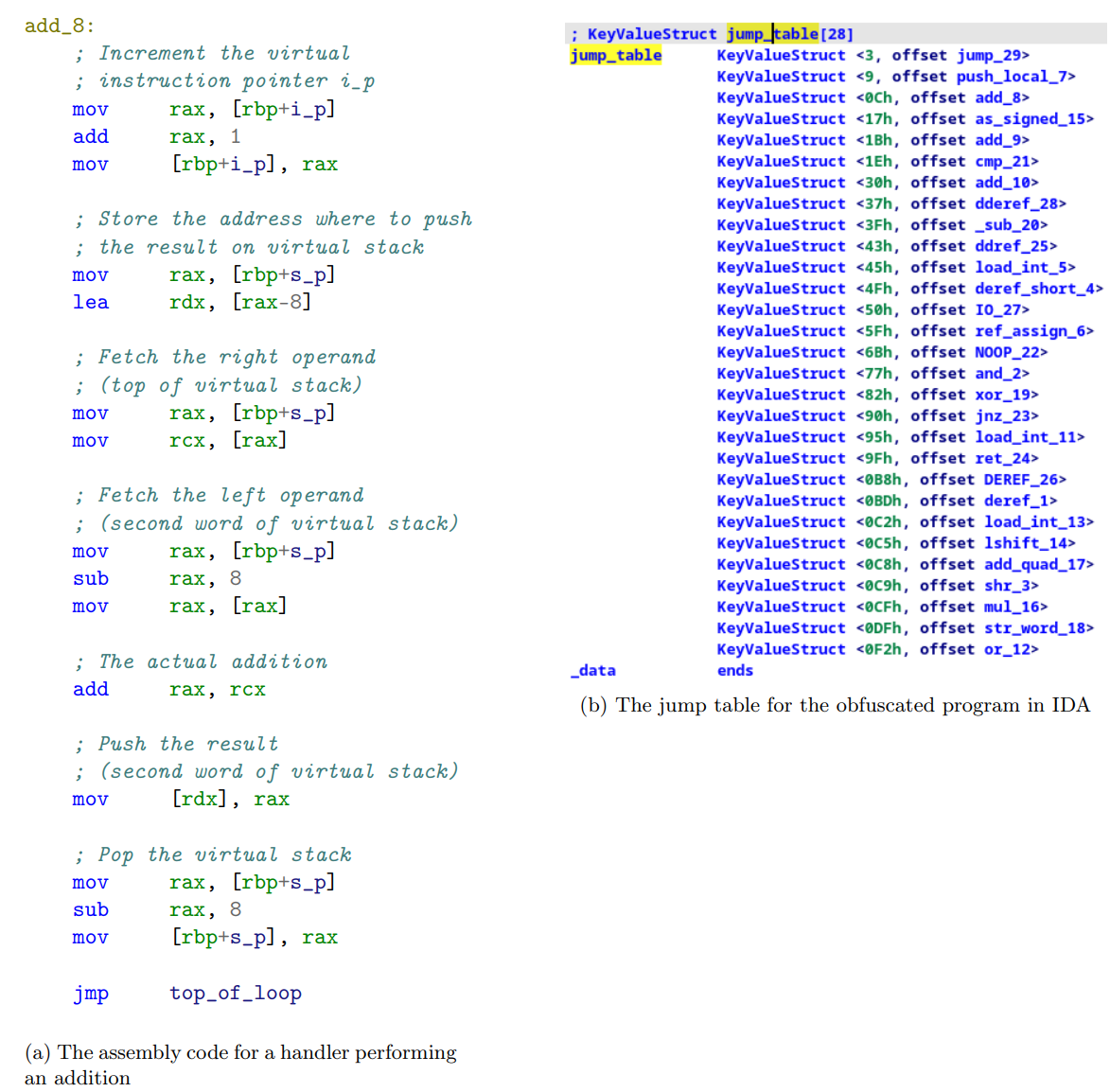
有了上述所有信息,我们现在可以编写一个 Python 脚本,用来反汇编我们的虚拟化程序。我们选择让每个 handler 输出伪 C 代码。图 25 展示了一个用于自定义反汇编器的 Python handler 示例;图 26 展示了去混淆后的程序片段(经过一些手动润色,如变量命名、指令归类等)。


最终生成的代码是可读的。我们将去混淆后的 C 代码编译,并测试了几个输入值,确认混淆前后的二进制程序在输入输出行为上一致。
总体而言,这个实验非常漫长且繁琐。我大约花了两天时间完成,而 Sebastian Millius(原始解题者)在处理所有 5 个挑战时大约用了 8 小时 [51]。尽管这看起来耗时还算合理,但需要注意的是:这些结果都是基于一个极其简单的程序(只有一个 if 语句)、简单的指令集,并且只使用了虚拟化一种混淆手段得出的。现实中的混淆程序往往包含多个混淆层,且程序规模要大得多。
尽管如此,这次实验仍然带给我们一些有价值的信息:
- 重建控制流图(CFG)非常困难。
- 手动去混淆虚拟化的二进制程序非常繁琐。
- 我们现在拥有了 challenge0-1 的去混淆版本(Tigress 官方并未提供这一版本)。
这次分析还帮助我们理解了混淆时使用的具体参数。事实上,挑战中提供的混淆命令是不完整的,像 VirtualizeDispatch 这样的参数是隐藏的。
我们现在可以确定,参数 VirtualizeDispatch 的值被设置为了 binary,这表明在指令码与 handler 地址的匹配过程中使用了二分查找。完整的混淆命令如下。
1 | |
6.2 自动去混淆策略
手动去混淆实验的耗时与困难,充分说明了自动化去混淆工具的必要性。在第一部分(I.3)中介绍的多种自动化去混淆策略中,我们最终选择了 Triton 的方法。选择 Triton [45, 42] 的原因是,它曾成功解决了 Tigress 提供的 6 个挑战中的 4 个,我们希望看看自己是否也能复现这些结果。
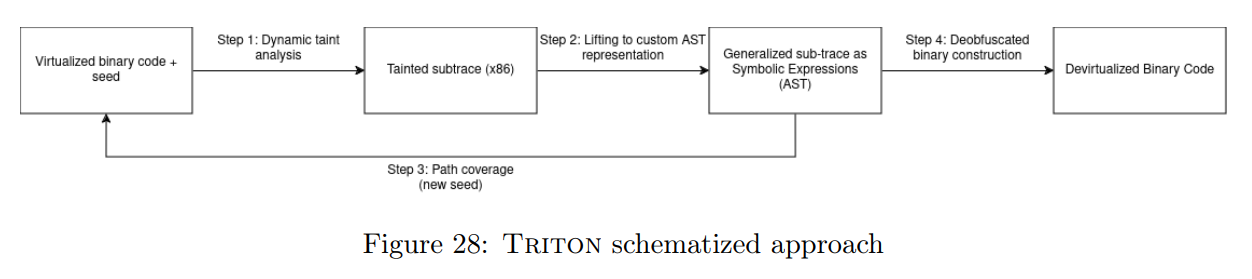
回顾一下,Triton 所采用的策略(在图 28 中有总结)如下:首先,它会通过不同的初始种子(seed)收集混淆程序的污点子路径(tainted sub-traces)。这些种子是通过符号执行计算出来的,目的是最大化代码覆盖率。接着,它会对这些子路径进行重建与优化,从而实现对二进制程序的去混淆。我们将在本报告的后续部分中详细解释这一过程是如何实现的。
6.3 Triton自动化去混淆的限制
为了更好地理解 Triton 的方法,我们下载了该工具,并尝试将其应用于部分 Tigress 挑战程序的去混淆。
使用 Triton 库,我们成功部分去混淆了 challenge0-1。我们并没有使用官方提供的脚本,而是基于 Triton 库和我们对论文的理解,尝试自己编写脚本。Triton 给出了非常不错的结果,但速度比较慢:仅污点分析就在我的机器上耗时约 20 秒。在文献 [43] 中,Jonathan Salwan 等人声称能在 9 秒内解决该挑战,这与我们的结果是一个数量级的,我也预期他们的脚本会比我的更快。
这个实验的关键结论是:Triton 在处理非常简单的程序(如 challenge0-1,仅为一个 if/else 语句)时,仍可能耗费十秒左右的时间。我们认为其中一个原因是 Triton 严重依赖符号执行,而符号执行本身就是出了名的慢。
如果我们希望去混淆更大、更复杂的程序,就需要一个更快的工具。
我们希望解决 Triton 的另一个限制是:Triton 使用内部的 AST 表达形式(抽象语法树),这使得它很难与其他已有工具进行集成和互操作。
6.3.1 一个假设:从优化开始
除了前面提到的限制之外,我们还提出了一个小小的改进思路:为什么不把优化步骤放在去混淆流程的最开始,而不是最后?
添加这个步骤可能会减少分析时间:代码更少 → 要分析的内容更少 → 运行时间更快。
这个想法很有趣,也促使我们着手开发一个新工具。然而,在实习期间我们没有足够的时间去验证这个假设。虽然优化模块已经加入到了工具中,但要真正观察到它带来的效果,我们需要更多被混淆的二进制样本,而这部分我们没有时间去充分测试。
7 MERMAID:一个使用 LLVM 的自动去混淆工具
我们在使用 Triton 时遇到的种种限制,促使我们开发了一个新工具:Mermaid。这个新工具的设计目标是为处理更大型的混淆二进制程序打下基础。因此,我们特别注重性能与模块化设计。与其构建一个庞大的一体化工具,我们更倾向于构建一套小型、可互操作的工具链,它们彼此协作,并都强烈依赖于 LLVM。
我们选择使用 LLVM,是因为它提供了强大的优化能力,并且已被广泛用于许多逆向工程项目中作为中间表示(IR)。我们希望,通过采用 LLVM 作为 IR,我们的工具能够更好地与现有工具集成。
在本次实习期间,我们已在 Mermaid 中实现了 Triton 去混淆策略中的大部分内容。然而,由于时间限制,我们尚未实现 Triton 中用于自动生成新种子以提升覆盖率的循环逻辑。
7.1 去混淆策略
虽然我们前面大多提到了 Triton,但实际上我们的去混淆策略更接近 Yadegari 等人 [57] 的工作。 我们的去混淆工具将比 Triton 或 Yadegari 等人编写的工具简单得多,但我们将充分利用 LLVM 的能力。尽管 Triton 也使用了 LLVM,但我们计划将 LLVM 放在我们工具的核心位置。
图 29 展示了 Mermaid 是如何对二进制程序进行去混淆的整体流程图。

7.2 混淆程序
在开发 Mermaid 的过程中,我们选用了 Collatz 猜想作为测试程序。
1 | |
Collatz 猜想指出,数列 $(u_n)$ 如下所示(见 公式 6),对于任意初始值 $u_0 \in \mathbb{N}$,最终都将收敛到 1:
$$
\forall n \in \mathbb{N},\quad u_{n+1} = \begin{cases} u_n / 2 & \text{if } u_n \equiv 0 \pmod{2} \ 3 \times u_n + 1 & \text{if } u_n \equiv 1 \pmod{2} \end{cases} \tag{6}
$$
我们之所以选择 Collatz,是因为它的控制流图(CFG)简单但具有代表性。它既包含了循环结构,也包含了条件分支。此外,Collatz 很容易嵌入我们 Tigress 挑战的模板中。
与 challenge0-1 相比,使用 Collatz 的最大优势在于:我们对代码、编译过程和混淆步骤拥有完全控制权。这种控制能力是 challenge0-1 无法提供的,它大大简化了分析与调试过程,使其更适合用于工具开发。
随后,我们使用 Tigress 混淆器 3.1 版本 对该程序进行了混淆,所使用的命令与 Tigress 挑战的challenge0-1中所用命令相同(见图 27)。
7.3 构建控制流图
对二进制程序进行去混淆的第一步是从该二进制中提取出被混淆函数的控制流图(CFG)。
7.3.1 静态分析面临的挑战
如前文中在前沿技术综述部分(见 I.1)所述,提取控制流图(CFG)并不是一项简单的任务。我们预计被混淆的函数会在其调度器(dispatcher)中使用间接跳转。而间接跳转的存在极大地增加了完成静态分析的难度。此外,IDA 无法成功还原 CFG 也说明了一个问题:我们不应该仅依赖静态分析。因此,我们选择采用动态方式重建部分控制流图(partial CFG)。
7.3.2 重构部分控制流图的动机
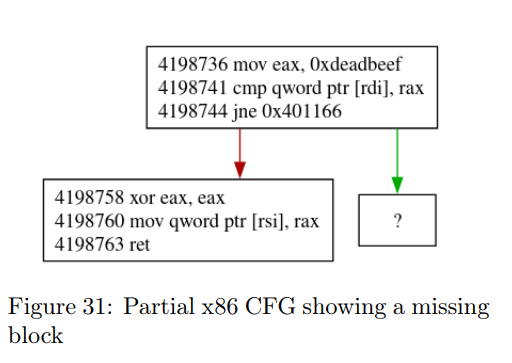
在动态重建控制流图(CFG)的过程中,我们并不能保证能够恢复出完整的 CFG。程序可能存在多个执行路径,而我们在执行过程中可能只访问了其中的一条路径。举一个简单的例子:假设程序有两个分支路径。 当输入值(如图 31 中的 qword ptr [rdi])等于某个常量(图中为 0xdeadbeef)时,我们才会进入第二条路径。 由于这个常量通常很难被猜中,因此我们在运行时很可能只会沿着第一条路径执行。
图 31 展示了一个部分控制流图(partial CFG)的示例。虽然我们没有探索到所有执行路径,但我们确实访问到了可能通向其他路径的那条分支指令。 因此,我们可以标记出“至少存在一个未被探索的执行路径”。 这个信息通常用一个带问号的块来表示(注意:这个“块”仅是可视化符号,实际缺失路径可能由多个基本块组成)。
7.3.3 动态重构部分控制流图
为了动态重建部分控制流图(partial CFG),我们首先使用 Unicorn 模拟器 [14] 对程序进行模拟执行,以获取一条执行轨迹(execution trace)。 我们选择使用模拟执行,是因为这看起来是一种更简单的策略。不过,实际上还有一些更高效的方案可以获取执行轨迹,例如 Intel Processor Trace(Intel PT) [23]。
在我们拿到执行轨迹之后,我们设计了一个简单的算法,用于根据轨迹重建控制流图(如图 1 所示)。

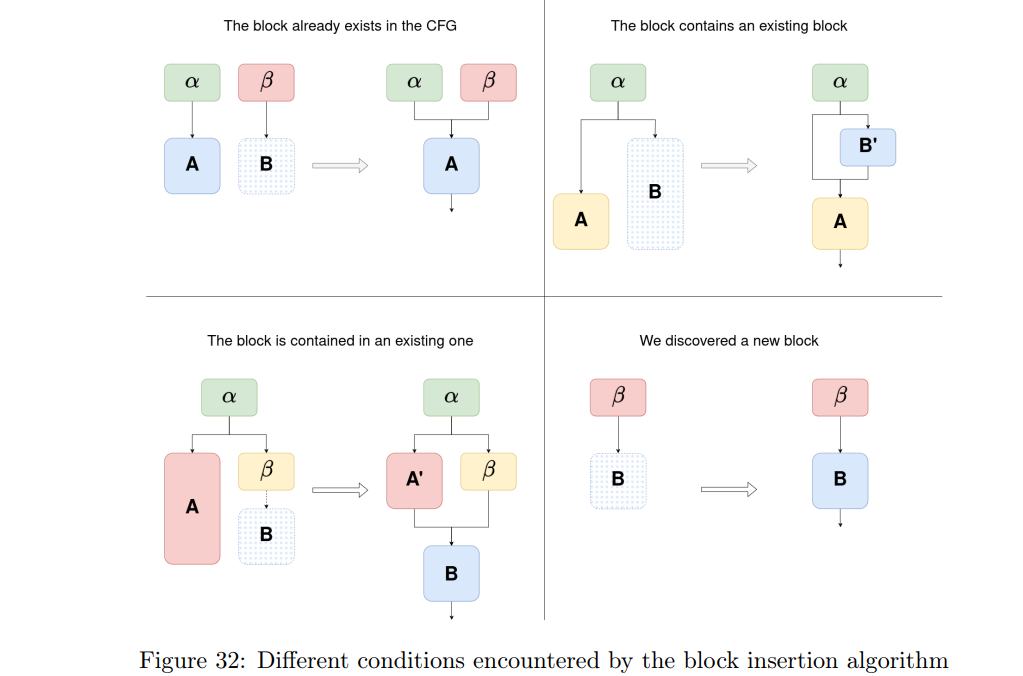
这个算法中较为复杂的部分是如何将代码块插入到 CFG 中(见算法 2)。 由于我们会在控制流指令处分割基本块,这就可能导致新块与已有的块发生重叠。 为了解决这个问题,我们的插入算法会确保:每一条指令在整个 CFG 中只出现一次。

7.3.4 实验结果
使用该算法,我们成功地重建了一个部分控制流图(partial CFG)。 这个 CFG 是不完整的,因为我们的执行轨迹仅来源于一个输入值,而对于其他输入值,程序可能存在其他执行路径。 例如,在图 31 中,我们的 CFG 缺少一条路径,该路径只有在输入等于 0xdeadbeef 时才会被执行。
为提高 CFG 的完整性,有多种策略可以采用。我们可以使用符号执行来生成新的输入值,以探索其他路径(这正是 Triton 所使用的策略)。我们也可以进行静态分析,来探测那些已知地址但尚未执行的基本块(就像图 31 中的例子:我们知道地址 4198744 + 2 = 0x40115a 上还有一个未探索的块)。
不过,对于本次实习来说,这种部分 CFG 已经足够使用。 这是因为根据我们的测试,不论输入为何,混淆后的 Collatz 程序中的所有代码块最终都会被访问到。
我们在附录中提供了原始 Collatz 函数的部分 x86 控制流图(附录 A.1)和混淆后 Collatz 函数的部分控制流图(附录 A.2)
在实际运行中,模拟并构建一个 CFG 耗时约 15 毫秒;相同输入下,原始 Collatz 程序运行仅需 0.5 毫秒。
7.3.5 LibCFG
在整个工作中,我们处理了大量的控制流图(CFG),希望能够对多种语言的 CFG 执行加载、存储和显示等常见操作。
调研了其他二进制导出工具(如 Quokka [37]、BinExport [4] 等),但没有找到合适的工具。因为本项目需要非常精确且与语言无关的 CFG 和指令信息,同时不需要数据段、符号等信息,并且需要支持 Amd64 和 LLVM IR 的统一表示。
基于这些原因,我们决定开发 LibCFG,这是一个用 C++ 编写的 CFG 交互库,支持通过 FlatBuffers 保存和加载 CFG,也支持用 Graphviz 进行显示。
为了确保多语言支持,我们提炼了 CFG 的通用定义,将 CFG 视为有向图,每个节点(Block)由一系列指令组成,Block 可以有多个父节点和子节点,指令包含地址但不假设地址的唯一性、连续性或递增性,且 CFG 必须有且仅有一个入口点(无父节点的 Block)。
基于此定义,我们实现了适配 Amd64、LLVM 和通用字符串语言的 LibCFG 适配器。
我们用 LibCFG 生成了本报告中的大部分 CFG,但目前程序在显示边颜色时存在问题,图中可能出现颜色错误的边,这只是美观上的问题,不影响功能。
7.3.6 Typing a CFG
在本项目中,我们接触到了 CFGgrind [41],它是一个基于 Valgrind [33] 的动态追踪工具,用于构建控制流图(CFG)。
CFGgrind 提出了一个有趣的概念——指令类型(instruction types),他们定义了五种类型的指令:
- standard:顺序执行到下一条指令
- jump:无条件跳转
- branch:有条件分支
- call:函数调用
- return:将控制权返回给调用者
我们对 CFGgrind 的设计进行了多处改动以集成到 LibCFG 中。 首先,我们去掉了 call 类型,因为它不符合我们的需求范围。其次,我们没有在指令级别添加类型,而是将类型赋予整个基本块(Block)。 在一个块中,除最后一条指令外,其它指令必然是 standard 类型(或者是 call,但我们已移除 call), 因此我们使用 CFGgrind 对最后一条指令的类型作为 LibCFG 块的类型。
我们的类型系统包含六种块类型:
- Standard:顺序流向下一条指令
- Jump:无条件跳转到已知地址
- IndirectJump:无条件跳转到未知地址
- Branch:有条件分支到已知地址
- IndirectBranch:有条件分支到未知地址
- Return:将控制权返回给调用者
这些类型足够通用,可以在不同语言环境下通用。 例如,Jump 类型可以代表 LLVM 中以 BR 指令结尾的块,Amd64 中以 JMP 指令结尾的块,或者 ARM 中以 B 指令结尾的块。
7.4 提升至LLVM IR
下一步的反混淆过程是将程序提升到 LLVM IR。在前一部分中,我们成功地从二进制文件中提取了一个 Amd64 控制流图(CFG)。这一步,我们希望将这个 Amd64 CFG 转换为 LLVM IR 的 CFG。
7.4.1 代码提升的优点
将二进制代码提升(lift)到中间表示(IR)可以简化分析步骤,原因有多方面。首先,IR 的设计更适合分析。例如,我们使用的 LLVM IR 采用了 SSA 形式,这极大地简化了优化过程,同时也简化了复杂指令的处理(如 Amd64 架构中的 AESDEC 指令)。其次,IR 提供了一种与平台无关的程序表示,经过转换后,我们可以不受原始架构(Amd64、ARM 等)的限制,统一应用各种分析流程。最后,IR,尤其是 LLVM IR,提供了一个标准,使得多个工具之间能够更方便地进行交互和通信。
7.4.2 过度表达问题
代码提升(lifting)是另一个难点。这或许让人惊讶,因为在编译过程中,LLVM IR 会被翻译成 Amd64 指令,那为什么反向操作这么困难呢?
大多数 Amd64 指令包含多种行为。例如,SUB 指令既执行减法运算,也会通过设置标志位实现比较功能。虽然编译器通常会更倾向于使用 CMP 指令来做比较,但有时也会用 SUB 指令来实现比较。然而,大多数情况下,SUB 指令仅被用作减法。
编译器可以选择使用指令的哪些行为以及多少行为。然而,对于已经生成的二进制代码,很难判断某条指令到底使用了哪些行为。这就导致我们的提升器必须对每条指令的所有行为都进行翻译。
然而,详尽描述每条指令的所有行为可能导致“过度表达”问题。所谓过度表达,是指程序在被提升到中间表示后,体积显著膨胀。
7.4.3 REMILL
我们选择使用 Remill [39] 作为代码提升的基础工具。Remill 是一个流行的指令提升工具,由 Trail of Bits 团队为其 McSema [31] 工具开发。
Remill 的工作原理是用 C++ 描述每条指令的语义。例如,图33展示了描述 Amd64 ADD 指令语义的 C++ 函数。使用 C++ 的优势在于开发者可以调用多种函数来处理常见操作(比如通过 Read 函数读取操作数),另外还可以利用 C++ 的模板技术在一个函数中描述多种操作。上述例子中,ADD 指令语义描述支持从内存、寄存器或立即数读取(分别由 S1 和 S2 类型处理)。

这段 C++ 代码随后使用 Clang 编译成 LLVM IR。这些定义全部存储在位于 <install-location>/share/remill/17/semantics/x86.bc 的 LLVM 模块中。在该模块里,我们找到了多个关于 ADD 指令的定义,包括针对整数、内存和浮点数的操作。
最后,Remill 通过“拼接”这些定义,实现对代码的提升(lifting)。
为了描述指令语义,Remill 使用一个特殊结构体 %state,它表示 CPU 的内部状态,且与架构相关。同时,Remill 使用一个名为 %MEMORY 的 void 指针来执行所有内存相关操作。这些变量在图34中得以体现,该代码示例演示了将 RDI 压入栈中,寄存器指针是通过先前的 %state 指针获得的。

尽管 Remill 工作量巨大,但代码提升本身尚未完成。实际上,Remill 并非一个完整的提升工具,而是自称为“供其他工具使用的库”。开箱即用时,Remill 生成的结果可能令人失望:生成的 LLVM IR 体积庞大,许多函数缺少定义,且 LLVM 优化能力受限,我们遇到了过度表达问题。
举个直观的例子,一条单独的 Amd64 ADD 指令用 Remill 提升成 LLVM IR 后,生成的模块竟然有 132 行之多!其实,LLVM 本身的 add 指令就足够了(当然,我们这里不考虑 Amd64 ADD 指令的各种副作用,比如进位标志)。
7.4.4 REMILL 内建函数
Remill 广泛使用了一些小型的未定义函数,称为内建函数(intrinsics)。在 Remill 的术语中,intrinsics 是留给库使用者自己实现的逻辑部分:
Remill 建模了指令逻辑及其对处理器和内存状态的影响,但不涉及内存访问行为或某些类型的控制流。对于这些行为的“实现”,Remill 交由生成的 bitcode 的使用者来完成。
Remill 并未提供这些函数的默认实现或文档说明。在实习的大部分时间里,理解每个 intrinsic 的确切含义和使用场景成了一个较大的难点。
一些 intrinsic 比较容易理解,例如图35中的 __remill_read_memory_8(注意其中使用了全局变量 RAM)。而有些 intrinsic 只是作为标记使用,比如 __remill_jump。

在 Saturn [21] 项目中,这些 intrinsic 是用 C++ 定义并编译成 LLVM IR 的。而对于 Mermaid,我们选择手写每个 intrinsic 的 LLVM IR 代码,理由是这样生成的 intrinsic 更短,更容易被优化。
7.4.5 SATURN
在我们的研究过程中,我们发现了一篇关于使用 LLVM 进行反混淆的工具的论文,该工具名为 Saturn。Saturn 构建在 Remill 之上,其作者针对 Remill 的一些不足提出了许多创新的解决方案。
尽管 Saturn 尚未公开发布,我们还是联系到了其作者,他们给予了我们许多富有洞见的建议。这些建议不仅涉及架构层面的整体设计,还包括一些具体的 LLVM 技巧。特别值得一提的是,他们帮助我们重新实现了其中一些巧妙的 LLVM Pass。
Saturn 的一个重要技巧是使用 LLVM 全局变量 RAM 来代替默认的内存指针。由于这是一个全局值,而不是每条指令都被重写的指针,LLVM 能够进行更有效的 别名分析(alias analysis),从而带来更好的优化效果。
7.4.6 重建CFG
Remill 在提升(lifting)单条指令方面表现不错,但若要提升整个控制流图(CFG),我们还需要做一些额外的工作。
在 Saturn 项目中,每个基本块(basic block)都会被提升为一个独立的函数。随后,另一个称为 控制流函数(control flow function) 的特殊函数会以正确的顺序“调用”这些基本块函数。这样做的好处是可以对每个基本块单独进行优化,同时也便于修改或分析控制流函数来操控整个 CFG。受 Saturn 启发,我们尝试了两种策略。
第一种策略是将每个基本块提升为一个独立的函数,函数之间相互调用。这样做的意图是让提升后的调用图(Call Graph)与原始程序的控制流图(CFG)保持一致。我们的想法是,通过 LLVM 的 函数内联(inlining) 优化,将所有小函数合并回来,从而(理论上)重新获得原始的控制流结构。这种方法的一个优点是避免直接处理复杂的 LLVM phi 节点。但实际情况却不尽人意。LLVM 在进行内联优化时,复制了大量的基本块,导致生成的新 CFG 与原始程序的结构严重不符。你可以在图 36 中看到这种策略的问题(尤其是图 36b):

第二种策略是创建一个具有正确控制流图(CFG)的骨架函数(skeleton function)。这个骨架函数在每个基本块中调用一个包含提升后的基本块的函数。图 37 展示了一个骨架函数的开头。控制流的管理依赖于程序计数器的值(在图 37 中为 %RIP_1,随后被加载到 %pc_after_inner_1 中)。
- 如果该基本块只有一个子块(例如,在图 37 中:
mermaid_connected_block_0),那么就直接跳转到这个子块。 - 如果该基本块有多个子块(例如,在图 37 中:
mermaid_connected_block_1),那么就对程序计数器的值进行switch分支选择,跳转到正确的子块。
我们希望在 LLVM 的常量传播优化过程中,程序计数器能够被具体化(concretized),从而使 LLVM 能够简化控制流图(CFG)。实际上,我们在一个基本块开始时是知道程序计数器的值的(如图 37 中,在 mermaid_connected_block_0 开始处的值为 419872620),LLVM 所需要做的就是在整个基本块中传播这个常量。通过实验我们验证了 LLVM 确实能够具体化程序计数器,而且最终生成的提升后的控制流图与最初的控制流图非常相似(见图 36c)。

我们决定采用基于程序计数器的方法,因为我们没有找到能够直接在 Remill 的提升(lifted)代码块中工作的方式。
7.4.7 包装器(Wrappers)
随后,我们添加了一些包装器,用于在执行提升后的程序之前将某些值具体化。在 Saturn 中,具体化是通过一个优化 pass 来完成的,但我们认为这种方式过于繁重。我们希望利用 LLVM 中小函数易于内联的优势来简化这一过程。
为此,我们编写了生成器,用于创建用于具体化某些寄存器的小函数(例如在 Amd64 架构中,我们可能希望具体化 RSP、RBP、FS、DF 等寄存器)。
我们还为函数类型创建了一个简单的包装器。由于我们知道目标函数只接受一个整数作为参数,并返回一个整数,我们创建了一个包装器,将函数原型从 void SECRET(int* input, int* output) 修改为 int SECRET(int input)。减少内存操作可以让 LLVM 的别名分析(aliasing)效果更好,从而实现更优的优化。
7.4.8 结果
图 38 展示了提升一个 Amd64 控制流图(CFG)所涉及的各个步骤的概览。
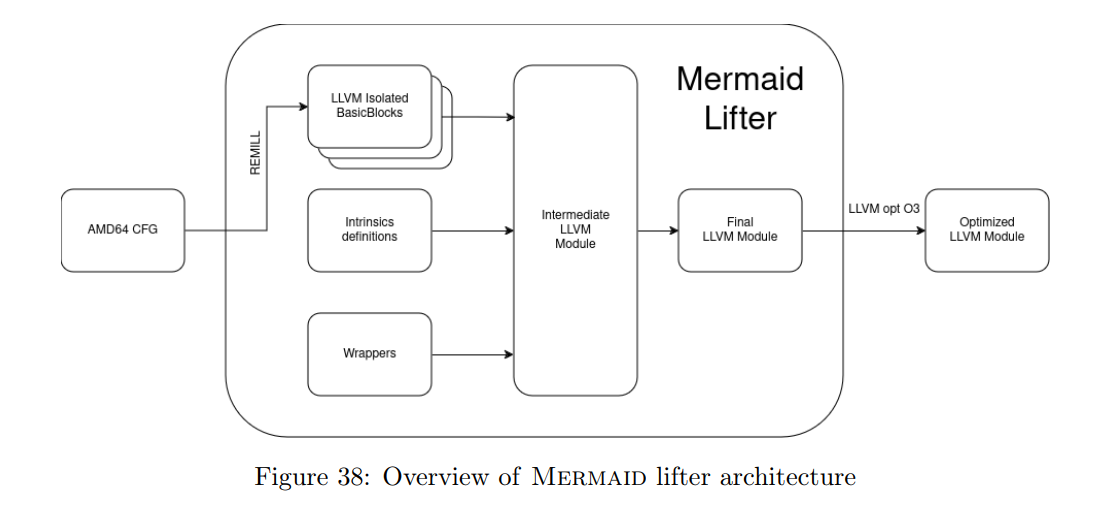
我们还在附录 A.2 中附上了混淆后的 Collatz 函数的 LLVM 控制流图,以及一个简化版本见图 39。
实验结果如下:
- 执行时间:提升混淆后的 Collatz 函数所耗时间不到 100 毫秒。生成的 LLVM 模块约有 4500 行代码。
- 优化:在使用
opt -O3进行优化后(耗时 200 毫秒),最终生成的模块精简为约 400 行代码。 - 控制流图大小:我们原始的 Amd64 控制流图共有 147 条指令,而提升后的 LLVM 控制流图包含 220 条指令,增加了约 50%。
7.4.9 图编辑距离(Graph Edit Distance)
在构建完成 lifter 之后,我们希望对其性能进行评估。最简单的策略是验证提升后的程序在一小组输入上的输入/输出行为是否与原始二进制程序一致。这种测试是有意义的,但不足以全面衡量 lifter 的性能。
实际上,我们不仅希望输入/输出行为一致,还希望控制流保持相似。例如,循环在提升过程中理应不会丢失。
然而我们也确实预期控制流图(CFG)会发生一些变化。原因在于,某些 Amd64 指令在 LLVM 中会被提升为多个基本块(例如 REP 指令)。因此,我们需要找到一种能衡量两个控制流图相似度的方法,而不仅仅是简单地尝试图结构匹配。
参考 Yadegari 等人的方法 [57],我们决定使用图编辑距离(Graph Edit Distance, GED)来比较控制流图。图编辑距离是一种衡量两个图之间相似度的指标,定义为将一个图转化为另一个图所需的最少编辑操作数。这些操作包括节点和边的添加与删除。计算 GED 是一个已知的 NP 难问题。不过,由于 GED 在网络分析与生物信息学等领域有广泛应用,因此存在许多近似算法。
我们选择基于 Pep Santacruz 和 Francesc Serratosa 所提出的一种近似算法(详见图 3)来实现我们的 GED 计算方法 [44]。

7.4.9.1 算法
该算法尝试匹配节点的小范围邻域(即节点的“星形”结构)。我们从一个种子节点开始(在我们的案例中是入口点),然后比较各个邻域,寻找最佳匹配。找到的匹配项会连同节点之间的距离一起加入队列中。接着,我们对队列进行迭代,每次选择距离最小的匹配项,并继续匹配其邻域。
7.4.9.2 距离
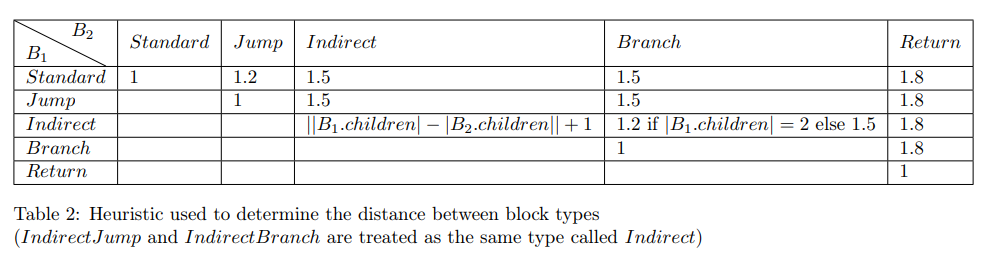
该算法高度依赖于节点之间的距离。由于我们需要比较用不同语言编写的控制流图(CFG),我们发现最有效的距离指标是之前定义的基本块类型。为此,我们构建了一张转换权重矩阵,用以表示将一种类型转换为另一种类型所需的代价。这个启发式方法见于表 2。在 MatchStar 函数中,我们使用带有这些距离权重的匈牙利算法(Hungarian algorithm)来求解最佳匹配。
7.4.9.3 局限性
遗憾的是,现有算法在比较控制流图(CFG)时并未产生令人满意的结果。举例来说,比较 Md5 算法的 Amd64 CFG 与其提升版本时,如图 40a 所示,我们注意到有一个基本块在两侧各有三个父节点。我们希望这两个基本块能够被正确匹配(尤其是它们各自的三个父节点也已被匹配的情况下)。
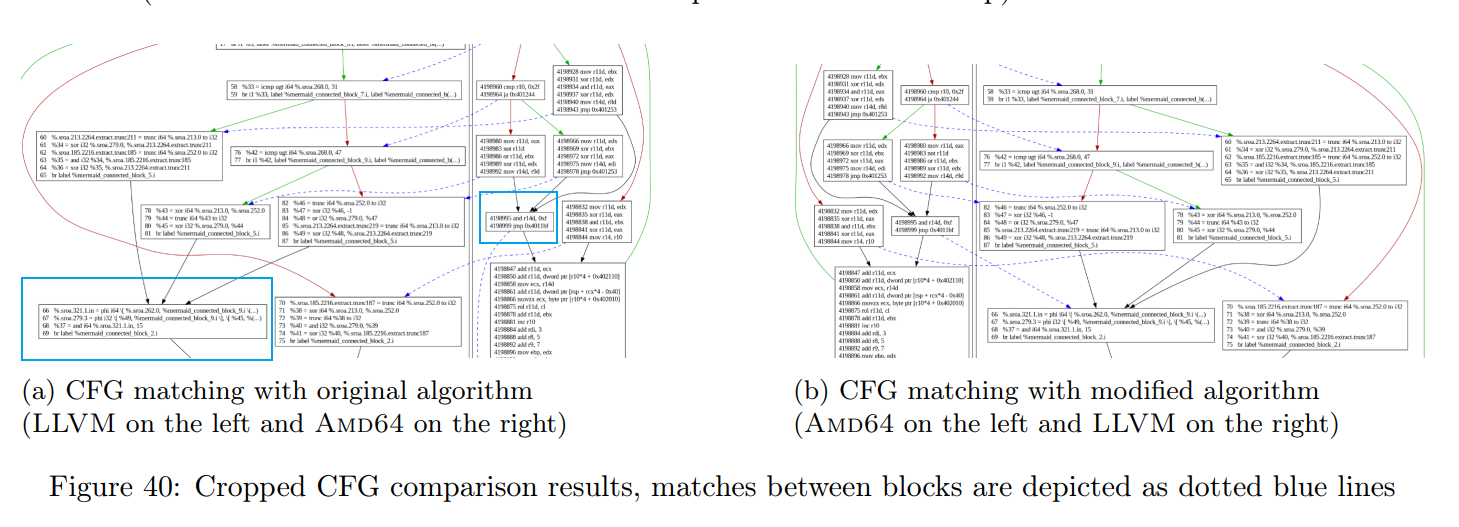
7.4.9.4 对算法的改进
我们为图匹配算法引入了一个新概念:确认偏差(confirmation bias)。我们希望匹配结果与之前的匹配决策保持一致(例如,希望匹配那些父节点已匹配的基本块)。为此,距离的计算现在依赖于之前的匹配情况:如果两个节点已经被匹配(即在匹配集合中),它们之间的距离视为 0。每当新增一个匹配时,我们都会重新计算所有节点间的距离以反映这一变化。这一过程对应算法 3 第 13 行调用的 PropagateConfirmationBias 函数,详细步骤见算法 4。

举例来说,在图 40 中,若不进行改进,两个各有三个父节点的节点之间的距离至少是 5(包括自身 1,三个父节点各 1,和一个子节点 1)。考虑到所有父节点已经被匹配后,距离可以降低到 2(自身 1,父节点均为 0,子节点 1)。
这一改进后的算法表现出优异的匹配效果,如图 40b 所示。该图比较同样也应用于混淆后的控制流图(CFG)。
7.4.9.5 终端输出
该算法不仅能够生成图形化结果来可视化控制流图之间的差异,还能提供差异的文本摘要(如图 41 所示)以及数值化的距离度量。这种输出形式在测试流水线(testing pipeline)中尤其有用,可以实现对比过程的自动化与量化分析。

7.4.9.6 调试符号
我们原本也考虑过在 Remill 单独提升每个基本块时,为提升后的模块添加调试符号。但在优化之后,这种做法可能会变得混乱(如图 42 中 Godbolt 所示)。此外,这种方法仅适用于由 Remill 提升生成的控制流图(CFG)。我们计划使用该图匹配算法在项目的不同阶段对控制流图进行比较,而不仅仅是在提升阶段。
7.5 污点分析
到目前为止,我们已经从一个 Amd64 二进制中提取出了函数的控制流图(CFG),并将该 Amd64 控制流图提升为 LLVM 控制流图。接下来,我们需要在程序上运行污点分析,以重构原始(即混淆之前的)控制流图。
这一分析高度依赖于污点分析的准确性。为了尽可能提高准确性,我们决定采用动态污点分析,正如 Triton 论文中所建议的那样。
然而,我们发现现有的支持 LLVM 的动态污点分析工具大多类似于 DataFlowSanitizer,且都需要源代码支持。而我们手头只有 LLVM 字节码,因此我们决定编写一个简易的自定义动态污点引擎。
7.5.1 解释器
编写一个污点分析引擎并非易事。为了在实习期间有限的时间内完成,我们决定借鉴 KLEE 的设计理念。实际上,动态污点引擎可以看作是一个简化版的符号执行器。
在分析了 KLEE 的源码之后,我们总结出它在提升解释执行效率方面的一些关键做法:
- 变量值表预构建:KLEE 构建了一个大型表格来存储每个变量的值。该表格及变量的 ID 都是在执行之前预先计算好的。
- 常量预处理:在“预执行阶段”中,KLEE 也会计算出所有的常量值。LLVM 的常量表达式可能非常昂贵,例如
GetElementPointer的常量表达式计算就较为复杂。
通过在解释执行之前完成这些准备工作,不仅能显著加快运行时性能,也能简化解释器的编写过程。
7.5.2 污点精度
我们的污点引擎仅在变量级别进行污点标记,而非位级别。这意味着如果 var1 是污点变量,并且我们有一条赋值语句 var2 ← var1 × 2,那么 var2 将整体被标记为污点,尽管它的最低有效位实际上并未被 var1 的污点影响。
Yadegari 等人 [57] 曾指出,在他们的前向污点传播中,需要进行位级别的污点分析才能达到足够的准确性。不过,我们在处理 Tigress 混淆样本时,即使只使用变量级别的污点分析,也取得了良好的效果。因此,我们决定继续采用这一较为简单但足够有效的变量级污点分析方式。
7.5.3 局限性
我们构建的污点引擎仍非常有限,目前只支持一种数据类型:整数。这些整数可以是有符号或无符号的,但必须不超过 64 位。
我们的实现不支持 LLVM 的大多数一等类型(first-class types),包括浮点数、元数据、向量等。不过,通过使用 LLVM 的 scalarizer pass 可以在一定程度上去除向量,从而实现对向量的有限支持。
此外,只有在某个测试程序的解释过程中确实需要某个指令时,该指令才会被添加到解释器中。因此,目前仍有许多 LLVM 指令和常量类型尚不被支持。
7.5.4 结果
利用 KLEE 的策略,以及使用机器整数而非多精度算术,使得该污点分析引擎运行速度相当快。
作为对比,LLVM 自带的解释器(lli)运行该混淆程序大约需要 20 毫秒,我们的污点分析引擎只需约 10 毫秒,而原生执行则不到 1 毫秒。与 lli 相比的提速,可以归因于我们对语言的支持较为有限,以及内存开销较大的预执行处理步骤。
再次强调,与其关注精确的执行时间,不如记住:这个分析步骤运行得很快。 若要更准确地评估性能,我们需要更多的测试程序,以及更长的程序样本。
我们实际上没有可靠的方法来验证污点分析引擎的准确性。 我们将结果与 Triton 的分析结果进行了人工对比,发现它们看起来是相似的。
以下是我们对提取后的控制流图(CFG)进行污点分析的结果。
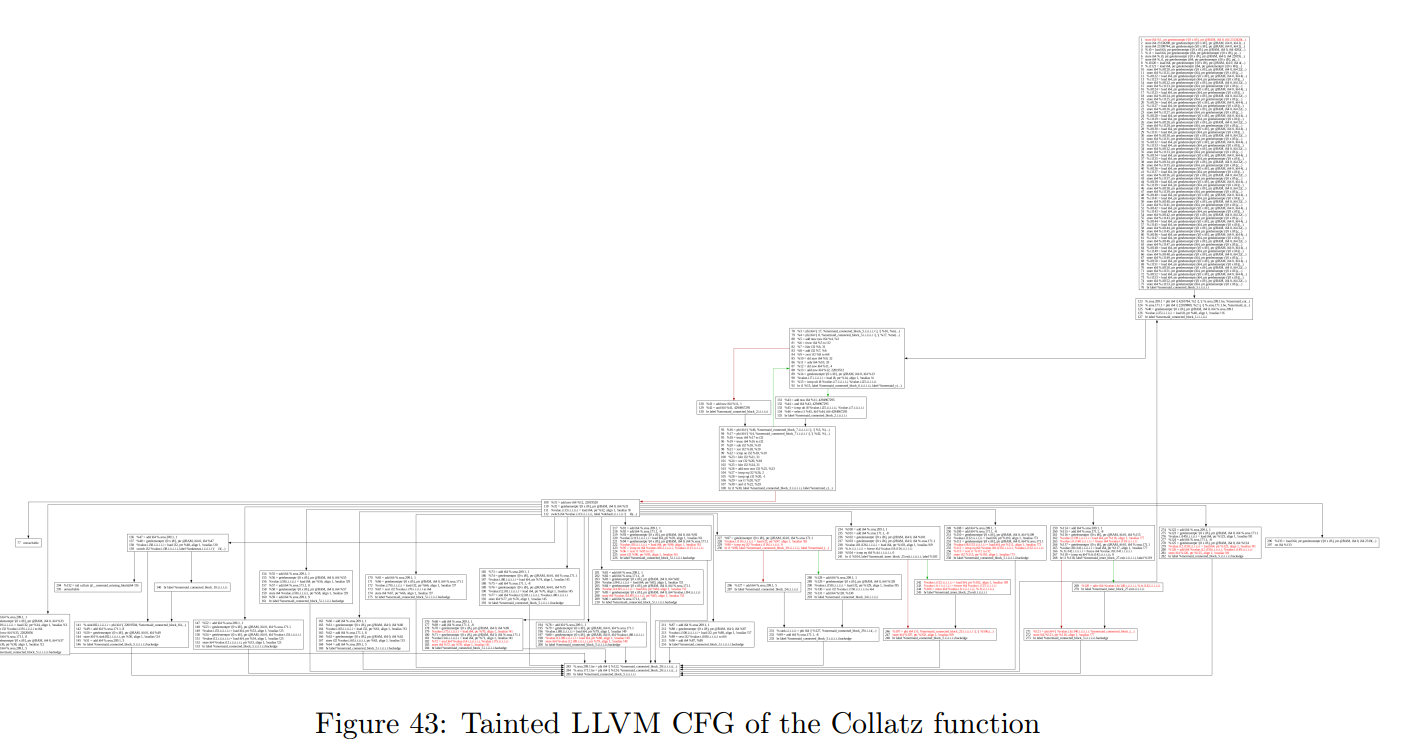
正如预期,仅某些处理函数内部被污染,并且只有一条分支指令被污染。 因此我们可以推测,这条指令正是原始程序中用来修改控制流的关键指令。
7.6 重构CFG
下一步是使用污点跟踪结果重建原始的控制流图(CFG)。在动态污点分析过程中,我们不仅构建了一个被污染的控制流图,还记录了我们访问过的每一个基本块。 这个记录就作为我们的执行轨迹,从而无需再进行一次额外的程序执行。
7.6.1 策略
Triton 依赖于符号执行,而 Yadegari 等人 [57] 使用了复杂的启发式方法,而我们采用了一种更简化(但鲁棒性较差)的方法。
7.6.1.1 想法
我们将未被污染的控制流指令(即不依赖用户输入的控制流指令)视为不透明谓词。实际上,只有被污染的控制流指令才可能导致我们的执行轨迹发生变化。 因此,我们创建了称为“多块(multiblock)”的大块结构,它由我们执行轨迹中一系列连续的基本块组成,并以一条被污染的控制流指令结尾。
7.6.1.2单一控制流指令假设
我们的策略依赖于完美的污点分析。然而,由于我们的污点引擎无法检测间接的数据流,有人可能会认为该策略无法奏效。幸运的是,在虚拟机(VM)的场景下,我们可以借助另一种假设:由于设计原因,虚拟机内部的处理函数(handler)在执行过程中通常会被多次复用。 因此,我们有理由相信,负责分支跳转的处理函数在某次执行中至少会被污染一次。于是我们可以假设:位于该地址处的控制流指令始终是被污染的。
7.6.1.3 例子
让我们来看一个模拟示例:一个程序从 0 计数到用户输入的值。图 44 展示了我们的初始程序。
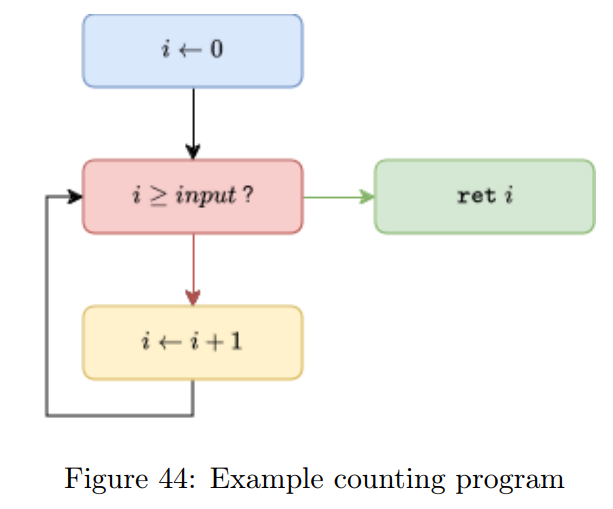
虚拟化之后,我们的程序可能如图 45 所示。虚拟机机制用紫色表示:它包含对虚拟程序计数器(VPC,vpc)的修改以及调度器(基本块 1)。

在我们的污点分析之后,我们能够构建出程序执行的轨迹。图 46 展示了当输入值为 2 时的执行轨迹。我们的污点分析还能够将包含用户输入的控制流图(CFG)指令标记为红色的污染指令。
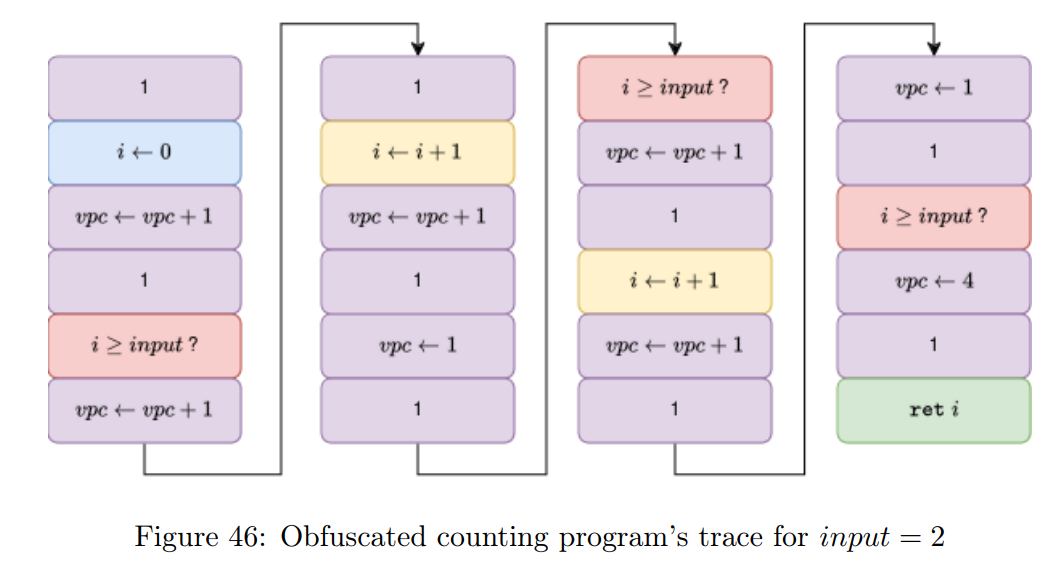
我们现在可以使用上文描述的算法来重建我们的控制流图(CFG):我们将基本块合并,直到遇到一个被污染的控制流指令(在我们的示例中是包含 “i ≥ input ?” 的红色基本块)。生成的 CFG 包含多块(multiblocks):由多个基本块组成的基本块。在构建 CFG 的过程中,我们会合并包含相同基本块的多块(在我们的示例中是包含黄色指令的多块)。图 47 展示了我们重建后的控制流图。
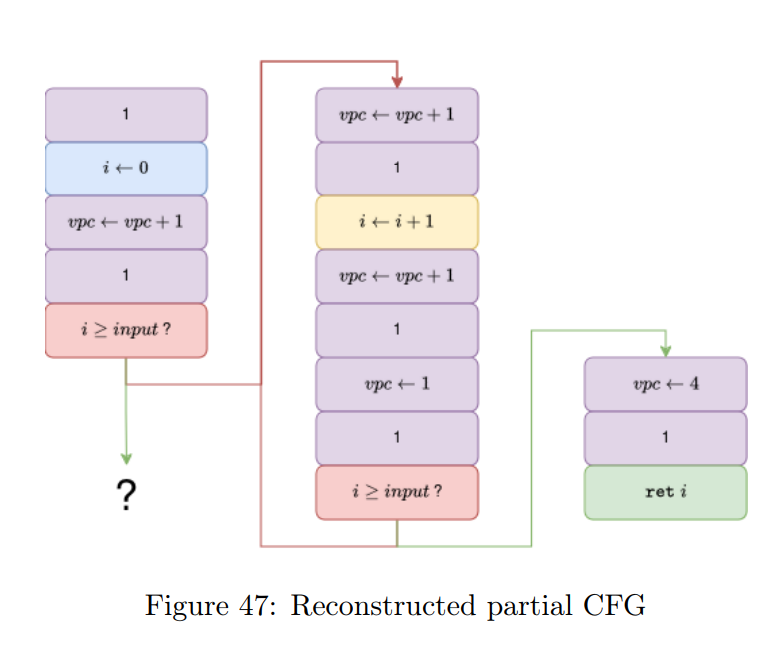
未使用任何额外启发式方法时,我们的算法会生成一个略显冗大的控制流图(CFG),其中包含重复的基本块(在我们的示例中是红色的 CFG 指令)。
此外,由于我们只能在分支指令处拆分基本块,因此原本能从跳转指令中获得的许多信息就会丢失。在我们的图中,跳转指令是“vpx ← 1”和“vpx ← 4”。
为简化 CFG,我们提出了一个简单的启发式方法:如果某个基本块的所有父块具有相同的后缀,我们就将该后缀提取到一个新的基本块中。
最终得到的 CFG 与原始 CFG 极为相似,但额外包含了虚拟机指令(用紫色表示)。
7.6.1.4 局限性
该算法在简化方面有所收获,但在正确性上有所损失。使用我们的算法,无法区分图 48 中的(病态)控制流图(CFG)。
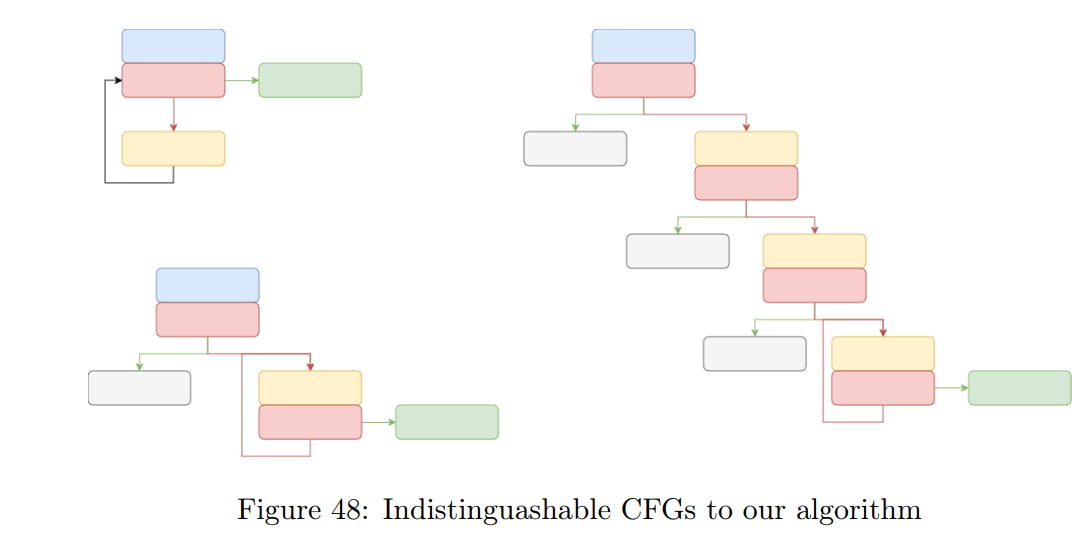
图 48 中详细列举的示例是程序的执行轨迹表现为循环的情况。要区分这些程序,我们需要能够识别虚拟程序计数器(VPC)(这是一个很难的问题)。 然而,尽管我们的算法并非始终正确,但大多数情况下能提供较好的结果,并且在实习期间我们运行的所有测试中均表现良好。
7.6.2 实现
在我们的污点执行轨迹中,我们首先移除所有未被污染的控制流图(CFG)指令(在 LLVM 中称为终结指令 Terminator instructions)。然后,我们仅使用被污染的 CFG 指令,采用与从执行轨迹构建 CFG(算法 1)非常相似的算法来重建 CFG。
然而,现在我们的地址可能属于多个多块(multiblocks)(一个基本块可以出现在多个多块中)。因此,为了比较多块,我们不能仅比较它们的结束地址。相反,我们通过比较所有组成的基本块,检查一个多块是否包含于另一个多块中。正如第 7.6.1.4 节所述,这种方法并不能保证正确性。
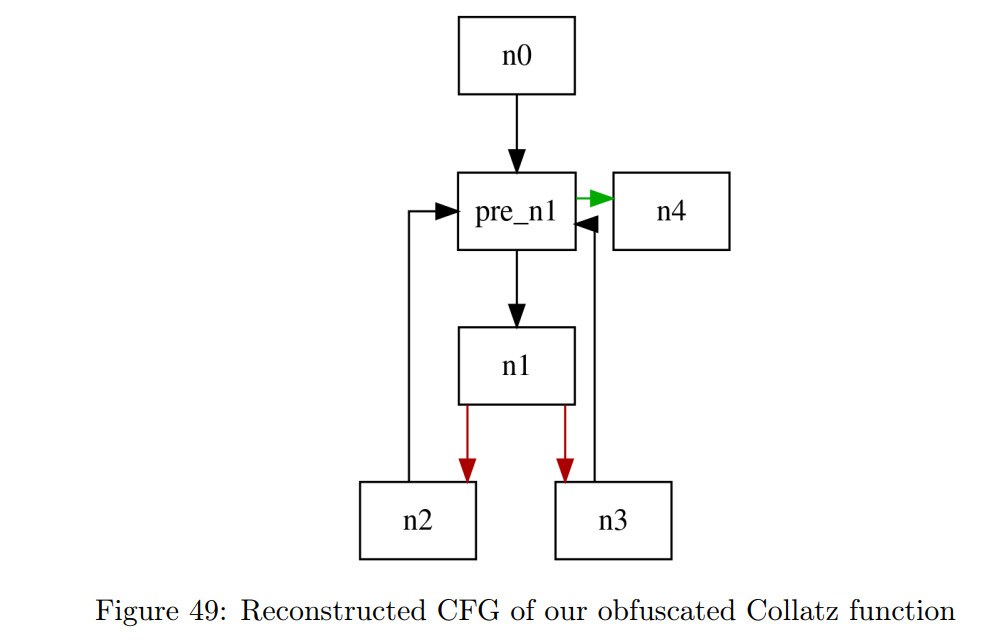
使用我们的实现,我们成功重建了被污染的 Collatz 函数的原始 CFG(图 49)。
7.7 从CFG到LLVM模块
在这个阶段,我们的控制流图(CFG)实际上并不是代码,而只是包含基本块 ID 的 CFG。在大多数编程语言中,将这种表示转换为可执行程序并不算太难。在之前针对 Amd64 的实验中,我们仅通过复制每个基本块并依次粘贴它们,就创建出了程序。但在 LLVM IR 中,情况就没那么简单了。
7.7.1 SSA带来的挑战
确实,在像 LLVM IR 这样的 SSA 语言中,不能简单地复制代码。
让我们考虑如果以一种简单粗暴的方式展开循环会发生什么。在图 50a 中,我们有一个简单的 LLVM 循环。程序对输入值进行两次自乘(结果是 pow(input, 4))。

如果我们以简单的方式展开循环,就和在 Amd64 中那样直接复制粘贴基本块,得到的就是图 50b 所示的程序。图 50b 中的程序并不是正确的 LLVM IR。因为数值(包括整数和标签)被重新定义了——而在 SSA 语言中这是不允许的。因此,我们需要找到一种方法来“修正”这个程序。
7.7.2 算法
这种方法的灵感来自 LLVM 中用于循环展开的代码。为了解决图 50b 中不正确的程序问题,我们需要一个 LLVM pass 来重新映射数值。这个过程分为两个阶段完成。
7.7.2.1 内部数值重新映射
第一遍遍历在每个基本块内部进行。我们将使用一个映射表,将“旧数值”映射到“新数值”。为此,我们访问每个表达式,向映射表中添加目标值,并尝试替换操作数。如果某个操作数不在映射表中,我们会将其加入未映射数值列表。我们用子块的标签初始化映射表。
例如,考虑图 50b 中展开循环的第一个基本块,该块在图 51 中变为 %loop0。开始时,映射表只包含子块标签(%loop 映射到 %loop1)。循环中的前两条指令是 phi 节点。在这个pass优化中,由于我们只关心内部数值,大部分指令会被忽略。但我们仍会将目标值加入映射表,因此会添加 %i → %l0_i 和 %x → %l0_x。当处理到第三条指令(mul)时,映射表中已包含这两个操作数,我们便可以将指令的操作数替换为新值:指令变为 mul nsw i32 %l0_x, %l0_x。同样,我们将目标值加入映射表(%x_x → %l0_x_x)。通过这种方式,我们能够生成图 51 中的 LLVM IR。

7.7.2.2 外部数值重新映射
上一个pass对于“修复”基本块结尾的指令非常有效,但某些数值(尤其是基本块开头的)可能仍未被映射。因此,第二个pass用于修复初始值和 phi 节点。
在这两种情况下,我们会在父块的映射表中查找对应的数值。例如,在 %end 块中,数值 %x_x 是未映射的。对于 %end 的每个父块(在此例中是 %loop1),我们会查找其映射值(本例中 %loop1 的映射表包含 %x_x → %l1_x_x,所以映射值为 %l1_x_x),并创建一个 phi 节点,将每个父块与其映射值对应起来(本例中 phi 节点为: phi i32 [ %l1_x_x, %loop1 ])。
7.7.3 结果
这两次遍历的结果如图 52 所示。在我们的实验中,这两个pass的耗时出乎意料地长,大约与污点分析的耗时相当(10 毫秒左右)。我们通过解释执行生成的程序,并将其输入输出行为与原始程序进行比较,从而验证了程序的正确性。

8 LLVM 优化
我们的去混淆流程利用了 LLVM 的优化功能来简化程序。在实习期间,我们曾短暂尝试创建专用的优化流程和新的 pass。我们观察到,-O3、-Os 和 -Oz 在我们的样本上表现相似。实际上,我们主要关注的是常量折叠(constant folding)和常量传播(constant propagation)这些 pass。我们创建了一个简单的优化流程 -Om,受 -O3 启发,但在其中加入了循环机制以多次运行某些 pass(见图 53)。我们只是简单地将这些 pass 执行了五次,而在 Saturn 中,pass 显然是一直应用到达到不动点为止。

该优化流程还包含自定义的 pass:ConstantConcretizationPass 和 MemoryCoalescePass。我们重新实现了这些为 Saturn 设计的 pass。 ConstantConcretizationPass 尝试从二进制中读取常量(例如虚拟化程序或跳转表)。 MemoryCoalescePass 是一个更复杂的 pass,它尝试对跟随在重叠的 store 指令之后的 load 指令进行具体化处理。
9 结果
从头到尾运行我们的去混淆流程耗时不到半秒。由于我们能够跳过一些序列化/反序列化操作,这一过程比逐个运行各个程序还要快。不过,我们认为相当一部分时间花在了文件的读写上,因为并不是所有程序都能直接通信。尽管我们能非常迅速地得到结果,但目前这些结果仍不完美。目前为止,循环结构以及多重指针尚未被正确去混淆。
9.1 循环不变量
虽然 LLVM 极大地简化了我们的代码(混淆后的模块从 13K 条指令减少到 400 条),但代码依然难以阅读。
经过仔细检查,我们发现一条指令是导致这一“阻塞”的关键(见图 54):

这里的 %4 是循环开始时的虚拟程序计数器(VPC),4210868 是循环第一次迭代时 VPC 的值,而 %.be 是一次迭代之后的 VPC 值。问题在于:LLVM 无法验证这是一个循环不变量。换句话说,LLVM 无法证明在绕过一次循环之后,程序会回到同一个位置。这个问题完全阻止了 LLVM 简化代码的能力,因为如果没有 VPC,LLVM 就无法获取指令或它们的立即数。
我们认为 Triton 可能没有遇到这个问题,因为符号执行应该可以证明 %4 是不变的。
9.2 手动修复
我们手动修复了循环不变量(将 phi 节点中的 %.be 替换为 4210868),以观察会发生什么。结果非常令人鼓舞。图 55 展示了去混淆后代码的一部分。在这段代码中,我们可以清楚地看到 Collatz 函数背后的逻辑:程序会进行奇偶性检查,然后要么除以二,要么乘以三加一。

9.2.0.1 噪声
然而,生成的代码仍然不完美,存在不少“噪声”(整个模块大约有 100 行)。我们发现主要有两个原因:
- 对 @RAM 的无效写操作:生成的程序中至少包含 40 处对全局变量
@RAM的未使用写操作。由于@RAM是外部全局变量,LLVM 无法将这些写操作识别为无效写入,因为理论上该变量可能在其他地方被读取。我们认为这个问题可以通过一个简单的 pass 来解决。 - 多级指针(指针的指针):一个更棘手的问题是多级指针的存在,这会阻碍 LLVM 的别名分析(antialiasing analysis)发挥作用。
9.3 回到我们的最初程序
出于叙述完整性的考虑,我们决定将我们的去混淆器运行在实习初期手动去混淆过的 Tigress 挑战样本上。在尝试运行我们的去混淆器时遇到了一些最后的困难,例如编译器选项不同、新出现的指令等问题。
经过一些调整后,我们成功地在最初的混淆程序 challenge0-1 上运行了去混淆流程。该程序不包含任何循环,因此我们的去混淆器没有遇到任何困难。脚本再次在不到一秒的时间内完成运行,并生成了一个部分的控制流图(CFG),该 CFG 可在附录 A.4 中查看。该 CFG 是不完整的,因为该程序存在两个执行路径,因此我们仅构建出了一半的控制流图。
为了方便对比,我们将去混淆后的 LLVM 模块重新编译,并在 IDA 中打开对应的二进制文件。图 56 展示了反编译后的代码片段,图 57 展示了对该代码手动清理后的版本(去除了未使用的 RAM 写操作)。


我们可以将图 57 中自动去混淆的代码片段与图 26 中手动去混淆的代码进行对比,可以看到其中的常量和操作是完全一致的。去混淆程序的其余部分见附录 B.1,我们认为该程序已经被很好地去混淆——尽管仍然存在一些“噪声”。
总结
在这次实习期间,我们深入探索了去混淆这一广泛主题,特别是自动去混淆器所面临的挑战。我们对当前技术进行了调研,尝试使用了一些先进工具,并开发了我们自己的工具。
调研结果表明,虚拟化混淆是目前效果最好的混淆技术之一。我们介绍了不同的去混淆工具是如何处理这类混淆的,并关注了其他混淆和去混淆策略,以提供对去混淆领域的全面入门介绍。
这次实习促使我们开发了一个基于 LLVM 的逆向工程工具:Mermaid。该工具能够构建、显示和保存控制流图(CFG),还可以将二进制文件转换为 LLVM IR,并在 LLVM 中执行动态污点分析。我们使用 Mermaid 成功地对一些用 Tigress 混淆的简单二进制程序进行了部分去混淆。 与 Triton 相比,这一去混淆过程运行速度非常快。
不过,Mermaid 仍然是一个不够成熟的工具:我们在混淆程序的特性和混淆类型方面做了很多简化假设。此外,目前的去混淆结果仍不完整,工具在处理循环结构时存在困难。
未来,我们希望通过去除这些假设来扩展 Mermaid 的能力。我们也希望集成一个抽象解释引擎,我们认为这有可能解决当前的循环不变量问题。
参考
[1] Dennis Andriesse, Xi Chen, Victor van der Veen, Asia Slowinska, and Herbert Bos. An {In-Depth} Analysis of Disassembly on {Full-Scale} x86/x64 Binaries. In 25th USENIX Security Symposium (USENIX Security 16), pages 583–600, 2016 (cited on page 3).
[2] Peter Ferrie. ANTI-UNPACKER TRICKS. https://pferrie.tripod.com/papers/unpackers.pdf (cited on page 10).
[3] Boaz Barak, Oded Goldreich, Rusell Impagliazzo, Steven Rudich, Salil Vadhan, and Ke Yang. On the (Im)possibility of Obfuscating Programs (cited on page 6).
[4] binexport. https://github.com/google/binexport (cited on page 29).
[5] Philippe Biondi, Raphaël Rigo, Sarah Zennou, and Xavier Mehrenberger. BinCAT: purrfecting binary static analysis (cited on page 4).
[6] Tim Blazytko, Moritz Contag, Cornelius Aschermann, and Thorsten Holz. Syntia: Synthesizing the Semantics of Obfuscated Code. In 26th USENIX Security Symposium (USENIX Security 17), pages 643– 659, 2017 (cited on page 12).
[7] Adam Burgher. BackdoorDiplomacy: Upgrading from Quarian to Turian. https://www.welivesecurity. com/2021/06/10/backdoordiplomacy-upgrading-quarian-turian/ (cited on page 1).
[8] Cristian Cadar, Daniel Dunbar, and Dawson Engler. KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs (cited on page 5).
[9] Cristian Cadar and Koushik Sen. Symbolic execution for software testing: three decades later. Communications of the ACM, 56(2):82–90, 2013. doi: 10.1145/2408776.2408795 (cited on pages 4, 5).
[10] Christian Collberg, Sam Martin, Jonathan Myers, and Jasvir Nagra. Distributed application tamper detection via continuous software updates. In Proceedings of the 28th Annual Computer Security Applications Conference, pages 319–328, 2012. doi: 10.1145/2420950.2420997 (cited on pages 6, 10, 13, 14).
[11] Christian Collberg, Clark Thomborson, and Douglas Low. Manufacturing cheap, resilient, and stealthy opaque constructs. In Proceedings of the 25th ACM SIGPLAN-SIGACT Symposium on Principles of Programming Languages, pages 184–196, 1998. doi: 10.1145/268946.268962 (cited on page 6).
[12] The MITRE corporation. MITRE ATT&CK. https://attack.mitre.org/ (cited on page 1).
[13] Patrick Cousot and Radhia Cousot. Abstract interpretation: a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Proceedings of the 4th ACM SIGACTSIGPLAN Symposium on Principles of Programming Languages, pages 238–252, 1977. doi: 10.1145/ 512950.512973 (cited on page 4).
[14] Hoang-Vu Dang and Anh-Quynh Nguyen. Unicorn: next generation cpu emulator framework. In 2015 (cited on page 27).
[15] Leonardo de Moura and Nikolaj Bjørner. Z3: An Efficient SMT Solver. In Tools and Algorithms for the Construction and Analysis of Systems, pages 337–340, 2008. doi: 10.1007/978-3-540-78800-3_24 (cited on page 5).
[16] Alessandro Di Federico, Mathias Payer, and Giovanni Agosta. Rev.ng: a unified binary analysis framework to recover CFGs and function boundaries. In Proceedings of the 26th International Conference on Compiler Construction, pages 131–141, 2017. doi: 10.1145/3033019.3033028 (cited on pages 3, 4).
[17] Adel Djoudi and Sébastien Bardin. BINSEC: binary code analysis with low-level regions. In Tools and Algorithms for the Construction and Analysis of Systems - 21st International Conference, TACAS 2015, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2015, London, UK, April 11-18, 2015. Proceedings, volume 9035, pages 212–217, 2015. doi: 10.1007/ 978-3-662-46681-0_17 (cited on pages 3, 4).
[18] Weiyu Dong, Jian Lin, Rui Chang, and Ruimin Wang. CaDeCFF: Compiler-Agnostic Deobfuscator of Control Flow Flattening. In Proceedings of the 13th Asia-Pacific Symposium on Internetware, pages 282–291, 2022. doi: 10.1145/3545258.3545269 (cited on pages 3, 11).
[19] Ninon Eyrolles, Louis Goubin, and Marion Videau. Defeating MBA-based Obfuscation. In Proceedings of the 2016 ACM Workshop on Software PROtection, pages 27–38, 2016. doi: 10.1145/2995306. 2995308 (cited on pages 7, 10, 12).
[20] Martin Co Fernando Merces Byron Gelera. KillDisk Variant Hits Latin American Finance Industry. https://www.trendmicro.com/en_us/research/18/f/new- killdisk- variant- hits- latinamerican-financial-organizations-again.html (cited on page 1).
[21] Peter Garba and Matteo Favaro. Saturn - software deobfuscation framework based on llvm. In Proceedings of the 3rd ACM Workshop on Software Protection, pages 27–38, 2019. doi: 10.1145/3338503. 3357721 (cited on pages 11, 33).
[22] Josh Grunzweig. Comnie Continues to Target Organizations in East Asia. https://unit42.paloaltonetworks. com/unit42-comnie-continues-target-organizations-east-asia/ (cited on page 1).
[23] Intel Processor Trace. https://grasland.pages.in2p3.fr/tp-perf/perf-script/intel-pt.html (cited on page 27).
[24] Minkyu Jung, Soomin Kim, HyungSeok Han, Jaeseung Choi, and Sang Kil Cha. B2R2: Building an Efficient Front-End for Binary Analysis. Proceedings 2019 Workshop on Binary Analysis Research, 2019. doi: 10.14722/bar.2019.23051 (cited on page 3).
[25] Pascal Junod, Julien Rinaldini, Johan Wehrli, and Julie Michielin. Obfuscator-LLVM – Software Protection for the Masses. In 2015 IEEE/ACM 1st International Workshop on Software Protection, pages 3–9, 2015. doi: 10.1109/SPRO.2015.10 (cited on pages 6, 8, 10).
[26] Johannes Kinder. Towards Static Analysis of Virtualization-Obfuscated Binaries. In 2012 19th Working Conference on Reverse Engineering, pages 61–70, 2012. doi: 10 . 1109 / WCRE . 2012 . 16 (cited on page 12).
[27] Patrick Kochberger, Sebastian Schrittwieser, Stefan Schweighofer, Peter Kieseberg, and Edgar Weippl. SoK: Automatic Deobfuscation of Virtualization-protected Applications. In Proceedings of the 16th International Conference on Availability, Reliability and Security, pages 1–15, 2021. doi: 10.1145/ 3465481.3465772 (cited on pages 8, 10, 11).
[28] T Laszlo and A Kiss. OBFUSCATING C++ PROGRAMS VIA CONTROL FLOW FLATTENING (cited on page 8).
[29] Chris Lattner and Vikram Adve. LLVM: a compilation framework for lifelong program analysis and transformation. In pages 75–88, 2004 (cited on page 3).
[30] Landon Curt Noll Leo Broukhis. The International Obfuscated C Code Contest. https://www.ioccc. org/ (cited on page 1).
[31] McSEMA. https://github.com/lifting-bits/mcsema (cited on page 31).
[32] miasm. https://github.com/cea-sec/miasm (cited on page 3).
[33] Nicholas Nethercote and Julian Seward. Valgrind: a framework for heavyweight dynamic binary instrumentation. SIGPLAN Not., 42(6):89–100, 2007. doi: 10.1145/1273442.1250746 (cited on page 30).
[34] Aina Niemetz and Mathias Preiner. Bitwuzla. In Computer Aided Verification - 35th International Conference, CAV 2023, Paris, France, July 17-22, 2023, Proceedings, Part II, volume 13965, pages 3– 17, 2023. doi: 10.1007/978-3-031-37703-7_1 (cited on page 5).
[35] Nathan Otterness. Tiny ELF Files: Revisited in 2021. https://nathanotterness.com/2021/10/ tiny_elf_modernized.html (cited on page 2).
[36] Chengbin Pang, Ruotong Yu, Yaohui Chen, Eric Koskinen, Georgios Portokalidis, Bing Mao, and Jun Xu. SoK: All You Ever Wanted to Know About x86/x64 Binary Disassembly But Were Afraid to Ask. 2021 IEEE Symposium on Security and Privacy (SP):833–851, 2021. doi: 10.1109/SP40001.2021. 00012 (cited on pages 2–5).
[37] Quokka. https://github.com/quarkslab/quokka (cited on page 29).
[38] Radare2. https://rada.re/n/ (cited on page 3).
[39] Remill. https://github.com/lifting-bits/remill (cited on pages 11, 31).
[40] H. Gordon Rice. Classes of recursively enumerable sets and their decision problems. Transactions of the American Mathematical Society, 74:358–366, 1953 (cited on page 2).
[41] Andrei Rimsa, José Amaral, and Fernando Pereira. Practical dynamic reconstruction of control flow graphs. Software: Practice and Experience, 51, 2020. doi: 10.1002/spe.2907 (cited on page 30).
[42] Jonathan Salwan. Triton. https://github.com/JonathanSalwan/Triton (cited on page 25).
[43] Jonathan Salwan, Sébastien Bardin, and Marie-Laure Potet. Symbolic deobfuscation: from virtualized code back to the original. In 2018, pages 372–392. doi: 10.1007/978-3-319-93411-2_17 (cited on pages 13, 14, 25).
[44] Pep Santacruz and Francesc Serratosa. Error-tolerant graph matching in linear computational cost using an initial small partial matching. Pattern Recognition Letters, 134:10–19, 2020. doi: https : //doi.org/10.1016/j.patrec.2018.04.003. Applications of Graph-based Techniques to Pattern Recognition (cited on page 37).
[45] Florent Saudel and Jonathan Salwan. Triton: a dynamic symbolic execution framework. In Symposium sur la sécurité des technologies de l’information et des communications, pages 31–54, 2015 (cited on page 25).
[46] Moritz Schloegel, Tim Blazytko, Moritz Contag, Cornelius Aschermann, Julius Basler, Thorsten Holz, and Ali Abbasi. Loki: Hardening Code Obfuscation Against Automated Attacks. In 31st USENIX Security Symposium (USENIX Security 22), pages 3055–3073, 2022 (cited on pages 3, 4, 6, 7, 9, 10, 12).
[47] Koushik Sen, Darko Marinov, and Gul Agha. CUTE: A Concolic Unit Testing Engine for C (cited on page 5).
[48] Yan Shoshitaishvili, Ruoyu Wang, Christopher Salls, Nick Stephens, Mario Polino, Andrew Dutcher, John Grosen, Siji Feng, Christophe Hauser, Christopher Kruegel, and Giovanni Vigna. SOK: (State of) The Art of War: Offensive Techniques in Binary Analysis. In 2016 IEEE Symposium on Security and Privacy (SP), pages 138–157, 2016. doi: 10.1109/SP.2016.17 (cited on pages 3–5).
[49] SMT-Comp 2023. https://smt-comp.github.io/2023/ (cited on page 5).
[50] Themida. https://www.oreans.com/Themida.php (cited on page 13).
[51] Tigress Challenge. http://tigress.cs.arizona.edu/challenges.html (cited on pages 14, 22, 24).
[52] Moritz Schloegel Tim Blazytko. The Next Generation of Virtualization based Obfuscators. Recon 2022 conference (cited on page 8).
[53] VMAttack. https://github.com/anatolikalysch/VMAttack (cited on page 10).
[54] vmprotect. https://vmpsoft.com/ (cited on pages 10, 13).
[55] Richard Wartell, Yan Zhou, Kevin W. Hamlen, Murat Kantarcioglu, and Bhavani Thuraisingham. Differentiating Code from Data in x86 Binaries. In Machine Learning and Knowledge Discovery in Databases, pages 522–536, 2011. doi: 10.1007/978-3-642-23808-6_34 (cited on page 2).
[56] Dongpeng Xu, Jiang Ming, Yu Fu, and Dinghao Wu. Vmhunt: a verifiable approach to partiallyvirtualized binary code simplification. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, pages 442–458, 2018. doi: 10.1145/3243734.3243827 (cited on page 10).
[57] Babak Yadegari, Brian Johannesmeyer, Ben Whitely, and Saumya Debray. A generic approach to automatic deobfuscation of executable code. In 2015 IEEE Symposium on Security and Privacy, pages 674– 691, 2015. doi: 10.1109/SP.2015.47 (cited on pages 13, 26, 37, 40, 42).
[58] Yongxin Zhou, Alec Main, Yuan X. Gu, and Harold Johnson. Information hiding in software with mixed boolean-arithmetic transforms. In Information Security Applications, pages 61–75, 2007 (cited on page 7).