一、前言 本文主要是通过分析VMProtect 1.81 Demo版加密后的程序,讲述VMP的基本结构,并尝试分析虚拟代码的功能以及虚拟代码还原。
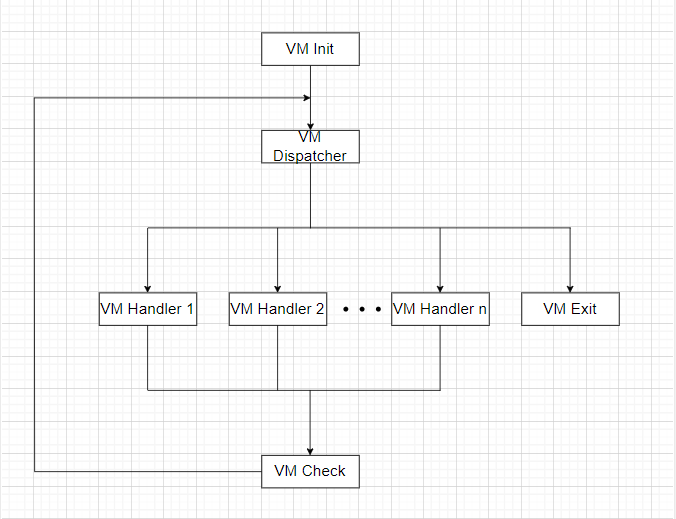
二、虚拟机结构 虚拟机保护技术是将程序的可执行代码转化为自定义的中间操作码(一字节或多字节),用以保护源程序不被逆向和篡改,这些中间操作码通过虚拟机解释执行,实现程序原来的功能。在这种情况下,如果要逆向程序,就需要对整个虚拟机结构进行逆向,理解程序功能,还需要结合操作码进行分析,整个程序逆向工程将会十分繁琐。以下是一个一般虚拟机结构:
虚拟机解释执行流程如下:
将真实环境的上下文入栈,初始化虚拟机运行所需要的环境,例如初始化VIP、VSP等。
根据VIP获取下一条虚拟指令的操作码,根据虚拟指令的操作码,跳转到对应VM Handler。
执行VM Handler,更新虚拟指令指针。
虚拟堆栈检查,检查虚拟栈空间是否充足。
重复执行2~4直至执行完所有虚拟指令字节码。
还原真实环境的上下文,退出虚拟机。
与虚拟机相关的数据结构如下:
VIP :虚拟指令指针,相当于x86-64中的RIP寄存器,指向下一条将要被执行的虚拟指令的地址。一般使用RSI寄存器来保存VIP。VSP :虚拟堆栈指针,相当于x86-64中的RSP寄存器,用来保存虚拟堆栈栈顶指针。一般使用RBP寄存器来保存VSP。VM Stack :虚拟堆栈,基于栈的虚拟机的一切指令的执行都借助虚拟栈来完成,例如加法指令,需要事先将两个操作数入栈,然后在栈上进行运算。VM Registers/VM Context :虚拟寄存器组,或者称之为虚拟机的上下文。一般使用RDI寄存器来指向虚拟寄存器组所在地址。VM Instruction :虚拟指令,也称为虚拟字节码,是虚拟机解释并随后执行的字节。每条虚拟指令至少由一个或多个字节。VM Opcode :虚拟指令操作码,每条虚拟指令中的第一个字节。IMM :虚拟指令中的立即数,这些立即数可能充当常量值、虚拟寄存器的索引值等。VM Handler :用于执行真实指令的虚拟代码片段,例如一个ADD指令对应一个VM Handler。根据 VM Opcode 选取对应的VM Handler来解释执行该操作码的具体功能。VM Handler Table :存放所有VM Handler的偏移地址的表。VM Opcode Table :存放虚拟指令字节码的表。
三、案例分析 本案例的样本来自于如何分析虚拟机系列(1):新手篇VMProtect 1.81 Demo - 吾爱破解 - 52pojie.cn 。样本的汇编代码如下,就是一个简单的加减同一个常量。
1 2 3 4 5 6 7 .text:00401000 sub_401000 proc near ; CODE XREF: start↓p
经过VMP保护后,变成如下所示
1 2 3 4 5 6 7 8 9 10 11 .text:00401000 ; void sub_401000()
这里有个典型的VMP入口特征:push call。push压入栈的数据是虚拟指令操作码表(VM Opcode Table)所在地址,然后通过call sub_40472C进入VM Entry。byte_404781 如下
1 2 3 4 5 6 7 .vmp0:00404781 byte_404781 db 0Eh, 0E8h, 81h ; DATA XREF: sub_401000↑o
VM Entry分析 1 2 3 4 5 6 7 8 9 .vmp0:0040472C push esi
首先一个很典型的特征就是VMP在创建虚拟机环境时,会将真实环境中寄存器的值入栈保存。
1 2 .vmp0:00404735 push ds:dword_404649
以上两条指令把要被操作的数据压入栈,这是基于栈的虚拟机的一个特点:数据的操作需要在栈上进行。那么可以确定这里应该是虚拟栈了。
1 .vmp0:00404740 mov esi, [esp+2Ch+arg_0] ;arg_0 = dword ptr 4
初始化esi,通过画堆栈图分析,可知 esi 的值为 byte_404781,也就是虚拟指令操作码表(VM Opcode Table)的基址。
1 2 3 .vmp0:00404744 mov ebp, esp
初始化 ebp 的值为 esp,指向虚拟栈的栈顶,然后创建一个新的栈帧,用于当作虚拟寄存器使用,edi指向虚拟寄存器的基址。
1 2 .vmp0:0040474E loc_40474E:
之后是获取虚拟栈栈顶数据,即虚拟指令操作码的偏移地址,然后加上虚拟操作码表的基址,此时 esi 指向第一个将要被执行的虚拟指令操作码。
VM Dispatcher分析 1 2 3 4 mov al, [esi] ;get vm opcode
根据虚拟指令操作码跳转到对应的VM Handler来执行相应功能。jpt_404757 是一个函数地址表,存放的是VM Handlers的偏移。
VM Handler分析 ADD——加法 ADDB——两个单字节数相加 1 2 3 4 5 6 7 loc_40476F:
虚拟栈栈顶的两个单字节数相加,结果存入后者所在位置,标志寄存器入真实栈,然后将真实栈顶元素(标志寄存器的值)存入到虚拟栈顶处。
参与加法运算的是[源ebp+2] 、[源ebp]的两个字节相加,而不是[源ebp+1] 、[源ebp]的两个字节相加,可能的原因是虚拟栈按两字节对齐。
ADDW——两个双字节数相加 1 2 3 4 5 6 7 loc_4045FC:
虚拟栈栈顶两个双字节数相加。此时虚拟栈提升两字节。虚拟栈顶的前四字节为运算产生的标志位,后两字节为运算产生的值。
ADDDW——两个四字节数相加 1 2 3 4 5 6 loc_404000:
虚拟栈栈顶两个四字节数相加。此时虚拟栈顶的位置不变。
SHR——逻辑右移 SHRB——单字节数逻辑右移 1 2 3 4 5 6 7 8 9 loc_404680:
从虚拟栈栈顶取出两个单字节数据,进行逻辑右移运算。将结果零扩展至双字节(右移结果存储在al中,但入栈的却是ax)。此时虚拟栈提升两字节。
SHRW——双字节数逻辑右移 1 2 3 4 5 6 7 8 9 loc_40454E:
从虚拟栈中依次取出双字节数据、单字节数据(作为位移值),进行逻辑右移运算。此时虚拟栈提升两字节。
SHRDW——四字节数逻辑右移 1 2 3 4 5 6 7 8 9 loc_404077:
从虚拟栈栈顶依次取四字节数据、一字节数据(作为位移值),进行逻辑右移运算。此时虚拟栈提升两字节。
SHRD——双精度逻辑右移 SHRDDW——四字节双精度逻辑右移 1 2 3 4 5 6 7 8 9 10 loc_404610:
从虚拟栈栈顶依次取两个四字节数据、一个一字节数据,进行双精度右移,这里仅将高位eax放入栈中。此时虚拟栈缩小两字节。
SHL——逻辑左移 SHLB——单字节数逻辑左移 1 2 3 4 5 6 7 8 9 loc_4045C0:
从虚拟栈中依次取出两个单字节数据,进行逻辑左移运算。将结果零扩展为双字节(结果存储在al,但入栈的却是ax)。此时虚拟栈提升两字节。
SHLW——双字节数逻辑左移 1 2 3 4 5 6 7 8 9 loc_404698:
从虚拟栈的栈顶中依次取出双字节数据、单字节数据(位移值),进行逻辑左移。此时虚拟栈提升两字节。
SHLDW——四字节数逻辑左移 1 2 3 4 5 6 7 8 9 loc_4046EF:
从虚拟栈的栈顶中依次取出四字节数据、单字节数据(位移值),进行逻辑左移。此时虚拟栈提升两字节。
SHLD——双精度逻辑左移 SHLDDW——四字节双精度逻辑左移 1 2 3 4 5 6 7 8 9 10 loc_4046BF:
从虚拟栈栈顶依次取两个四字节数据、一个一字节数据,进行双精度左移。此时虚拟栈缩小两字节。
NAnd——先非后与 NAndB——两个单字节数据先非后与 1 2 3 4 5 6 7 8 9 10 11 loc_404591:
从虚拟栈中依次取出两个双字节数据,实际上是低位一字节先进行非运算,然后再进行与运算。此时虚拟栈提升两字节。
NAndW——两个双字节数据先非后与 1 2 3 4 5 6 7 8 loc_404041:
对虚拟栈栈顶的四字节取反,然后分成两个双字节数进行与运算。此时虚拟栈提升两字节。
NAndDW——两个四字节数据先非后与 1 2 3 4 5 6 7 8 9 10 loc_40451A:
从虚拟栈栈顶依次取两个四字节数据,先进行非运算,然后与运算。此时虚拟栈顶位置不变。
PushConst——虚拟指令中的立即数入栈 PushConstB——单字节立即数入栈 1 2 3 4 5 6 loc_4044E4:
取虚拟指令中的操作数(单字节),零扩展至单字,然后入栈。此时虚拟栈提升两字节。
PushConstW——双字节立即数入栈 1 2 3 4 5 6 loc_40464D:
取虚拟指令中操作数(两字节),将其入栈。此时虚拟栈提升两字节。
PushConstDW——四字节数入栈 1 2 3 4 5 6 loc_40462B:
取虚拟指令中操作数(四字节),将其入栈。此时虚拟栈提升四字节。
PushConstCBDE——单字节立即数符号扩展至四字节并入栈 1 2 3 4 5 6 7 8 loc_40453B:
取虚拟指令中操作数(单字节),符号扩展成双字,然后入栈。此时虚拟栈提升四字节。
PushConstCWDE——双字节立即数符号扩展至四字节并入栈 1 2 3 4 5 6 7 loc_4044BE:
取虚拟指令中的操作数(两字节),符号扩展至双字,然后入栈。此时虚拟栈提升四字节。
PushReg——将指定虚拟寄存器的值入栈 PushRegB——取指定虚拟寄存器的单字节数据入栈 1 2 3 4 5 6 7 loc_4044D0:
从虚拟指令中取出操作数(单字节),作为虚拟寄存器的索引值,然后取出对应的虚拟寄存器中的值(单字节),将其入栈。此时虚拟栈提升两字节。
sub esi, 0FFFFFFFFh等价于 add esi, 1
PushRegW——取指定虚拟寄存器的双字节数据入栈 1 2 3 4 5 6 7 loc_4045E9:
从虚拟指令中取出操作数(单字节),作为虚拟寄存器的索引值,取出对应虚拟寄存器的数据(双字节),将其入栈。此时虚拟栈提升两字节。
PushRegDW——取指定虚拟寄存器的四字节数据入栈 1 2 3 4 5 6 loc_4045AF:
虚拟指令的操作码(单字节)与常量0x3C进行与运算,作为虚拟寄存器的索引值,取出对应虚拟寄存器中的值(四字节),将其入栈。此时虚拟栈提升四字节。
PopReg——将栈顶数据加载到指定虚拟寄存器中 PopRegB——加载栈顶一字节数据到指定虚拟寄存器中 1 2 3 4 5 6 7 loc_404568:
从虚拟指令中取出一字节操作数作为虚拟寄存器索引,取虚拟栈栈顶的两字节数据,将其存储到对应虚拟寄存器中,实际存储低位(一字节)。此时虚拟栈缩小两字节。
PopRegW——加载栈顶两字节数据到指定虚拟寄存器中 1 2 3 4 5 6 7 loc_4046DA:
从虚拟指令中取出一字节操作数作为虚拟寄存器索引,然后取虚拟栈栈顶的两字节数据,将其存入对应虚拟寄存器中。此时虚拟栈缩小两字节。
PopRegDW——加载栈顶四字节数据到指定虚拟寄存器中 1 2 3 4 5 6 loc_404058:
虚拟指令的操作码(一字节)与0x3C进行与运算,取出虚拟栈栈顶的四字节数据,将其存放到指定的虚拟寄存器中。此时虚拟栈缩小四字节。
PushVSP——虚拟栈指针入栈 PushVSPW——虚拟栈指针低位两字节入栈 1 2 3 4 5 loc_40463B:
虚拟栈的栈顶指针入栈(低位两字节)。此时虚拟栈提升两字节。
PushVSPDW——虚拟栈指针四字节入栈 1 2 3 4 5 loc_4046B2:
虚拟栈的栈顶指针入栈(四字节)。此时虚拟栈提升四字节。
PopVSP——将栈顶数据加载到虚拟栈指针寄存器中 PopVSPW——加载栈顶两字节数据到虚拟栈指针寄存器中 1 2 3 loc_404532:
虚拟栈栈顶的两字节数据加载到虚拟栈指针寄存器中。此时虚拟栈顶变化未知。
PopVSPDW——加载栈顶四字节数据到虚拟栈指针寄存器中 1 2 3 loc_40457C:
虚拟栈栈顶的四字节数据加载到虚拟栈指针寄存器中。此时虚拟栈顶变化未知。
Store——写内存 StoreB——单字节数据写入指定内存中 1 2 3 4 5 6 loc_4044AE:
从虚拟栈中依次取四字节数据(内存地址)、一字节数据(待存储的值),将一字节数据存储到四字节数据所指向的内存中。此时虚拟栈缩小六字节。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 6 loc_40475E:
StoreW——双字节数据写入指定内存中 1 2 3 4 5 6 loc_4044F6:
从虚拟栈中依次取四字节数据(内存地址)、两字节数据(待存储的值),将两字节数据存储到四字节数据所指向的内存中。此时虚拟栈缩小六字节。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 6 loc_404706:
StoreDW——四字节数据写入指定内存中 1 2 3 4 5 6 7 loc_404670:
从虚拟栈栈顶依次取两个四字节数据,前者作为内存地址,后者作为待存储的值,然后将值存储到对应内存中。此时虚拟栈缩小八字节。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 6 loc_4045D8:
Load——读内存 LoadB——加载指定内存的单字节数据到虚拟堆栈中 1 2 3 4 5 6 loc_40465F:
从虚拟栈顶中取出四字节数据作为内存地址,从对应地址中取出单字节数据,零扩展至单字后将其入栈。此时虚拟栈缩小两字节。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 6 loc_40449C:
LoadW——加载指定内存的双字节数据到虚拟堆栈中 1 2 3 4 5 6 loc_404508:
从虚拟栈中依次取四字节数据作为内存地址,取出对应内存的两字节数据,将其压入栈。此时虚拟栈缩小两字节。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 6 loc_404719:
LoadDW——加载指定内存的四字节数据到虚拟堆栈中 1 2 3 4 5 loc_404584:
取虚拟栈栈顶的四字节数据作为内存地址,然后取对应内存地址的四字节数据,将其压入栈。此时虚拟栈顶位置不变。
另一种使用堆栈段寄存器 ss 的情况:
1 2 3 4 5 loc_404069:
VM Exit分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 loc_40408E:
按照vm_entry入栈顺序进行逆序出栈,还原本机环境。
VM Check分析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 //栈空间是否充足
先检查栈空间是否充足,如果充足的话,跳转到vm_dispatcher,否则进行栈空间调整然后再跳转到vm_dispatcher。
虚拟代码还原 虚拟代码还原成一级虚拟指令 这里借助OllyDBG的Trace功能,跟踪程序执行的代码流,使用方法如下:
在菜单栏中点击 E 按钮(或者快捷键Alt+E)打开可执行模块窗口,右键主模块,选择”添加模块到运行跟踪协议“( Limit run trace protocol to selected module),表示 Trace 时记录该模块的所有地址,其他模块(如系统模块)不进行记录。
在菜单栏中点击选项->选项按钮(或者快捷键Alt+o),选择运行跟踪页面(Run Trace),勾选记住内存(Remember memory)。
在菜单栏中点击跟踪->跟进(Trace -> Trace into ,或者快捷键 Ctrl + F11),开始记录程序运行时的代码流。
在菜单栏中点击 … 按钮,打开运行跟踪窗口,右键日子记录文件(Log to file), 在保存时勾选添加可用目录(Add available contents) 和独立列标签(Separate columns with tabs)。
通过VM Handler的分析,已经知晓了这些指令类型,通过地址与一级虚拟指令的映射关系,可以初步根据代码流将虚拟代码还原成一级虚拟指令代码流,但是这些一级虚拟指令在不同环境下,操作数是不同的,因此还需要根据OD Trace到的寄存器和内存再做进一步优化。我这里偷点懒,使用的方法仅针对该样本,并不是一个通用的方法:找到一级虚拟指令地址后,选取该Handler中合适的指令,从记录到的上下文环境中提取操作数,手动执行运算得到结果。
具体代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 import refrom typing import Dict class insnContext :str int Dict [str , str ]Dict [str , str ]def __init__ (self, insn: str , addr: int , memory: Dict [str , str ], regs: Dict [str , str ] ):def getRegValue (self, reg: str ) -> str :return self.regs.get(reg)def getMemValue (self ) -> str :next (iter (self.memory.items()))return valuedef parseInsnStream (insn_stream: bytes ) -> insnContext:b'\t' )int (insn_line[1 ].decode(), 16 )2 ].decode()dict (re.findall(r'\[([a-fA-F0-9]{8})]=([a-fA-F0-9]{8})' , insn_line[3 ].decode()))dict (re.findall(r'([a-zA-Z]{3})=([a-fA-F0-9]{8})' , insn_line[4 ].decode()))return context0x40476F : "ADDB" ,0x4045FC : "ADDW" ,0x404000 : "ADDDW" ,0x404680 : "SHRB" ,0x40454E : "SHRW" ,0x404077 : "SHRDW" ,0x404610 : "SHRDDW" ,0X4045C0 : "SHLB" ,0x404698 : "SHLW" ,0x4046EF : "SHLDW" ,0x4046BF : "SHLDDW" ,0x404591 : "NAndB" ,0x404041 : "NAndW" ,0x40451A : "NAndDW" ,0x4044E4 : "PushConstB" ,0x40464D : "PushConstW" ,0x40462B : "PushConstDW" ,0x40453B : "PushConstCBDE" ,0x4044BE : "PushConstCWDE" ,0x4044D0 : "PushRegB" ,0x4045E9 : "PushRegW" ,0x4045AF : "PushRegDW" ,0x404568 : "PopRegB" ,0x4046DA : "PopRegW" ,0x404058 : "PopRegDW" ,0x40463B : "PushVSPW" ,0x4046B2 : "PushVSPDW" ,0x404532 : "PopVSPW" ,0x40457C : "PopVSPDW" ,0x4044AE : "StoreB" ,0x40475E : "StoreB" ,0x4044F6 : "StoreW" ,0x404706 : "StoreW" ,0x404670 : "StoreDW" ,0x4045D8 : "StoreDW" ,0x40465F : "LoadB" ,0x40449C : "LoadB" ,0x404508 : "LoadW" ,0x404719 : "LoadW" ,0x404584 : "LoadDW" ,0x404069 : "LoadDW" with open (r".\trace.txt" , "rb" ) as f:1 :-2 ]0 len (insn_stream)while step < end:1 if ctx.addr in handler_keys:'' if mnemonic == "PushRegDW" :2 ])'EDX' )int (ctx.getRegValue('EAX' ), 16 ) / 4 "PushRegDW R%d; R%d = 0x%s" % (reg_index, reg_index, reg_value)elif mnemonic == "PopRegDW" :2 ])'EDX' )int (ctx.getRegValue('EAX' ), 16 ) / 4 "PopRegDW R%d; [ebp] = 0x%s" % (reg_index, reg_value)elif mnemonic == "PushConstDW" :2 ])"EAX" )"PushConstDW 0x%s;" % immelif mnemonic == "PushConstCWDE" :3 ])"EAX" )"PushConstCWDE 0x%s;" % immelif mnemonic == "ADDDW" :"EAX" )hex (int (ebp_4, 16 ) + int (ebp_0, 16 ))[2 :].zfill(8 ).upper()"ADDDW [ebp+4], [ebp+0]; [ebp+4] = 0x%s, [ebp] = 0x%s, [ebp+4]+[ebp] = 0x%s" % (ebp_4, ebp_0, result)elif mnemonic == "LoadDW" :"EAX" )"LoadDW [[ebp]]; [ebp] = 0x%s, [[ebp]] = 0x%s" % (mem_addr, mem_value)elif mnemonic == "StoreDW" :2 ])"EDX" )"EAX" )"StoreDW [[ebp+0]], [ebp+4]; [ebp] = 0x%s, [ebp+4] = 0x%s" % (mem_addr, value)elif mnemonic == "NAndDW" :"EAX" )hex (((~int (ebp_4, 16 )) & (~int (ebp_0, 16 )) & 0xffffffff ))[2 :].zfill(8 ).upper()"NAndDW [ebp+4], [ebp+0]; [ebp] = 0x%s, [ebp+4] = 0x%s, ~[ebp+4] & ~[ebp]=0x%s" % (ebp_0, ebp_4, result)elif mnemonic == "PushVSPDW" :'EBP' )'PushVSPDW; EBP = %s' % ebp else :print ("unknow vm insntruction at address %s, vm_insn is %s" % (hex (ctx.addr).upper(), mnemonic))continue print (vm_insn_info)
最终得到一级虚拟指令如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 PopRegDW R3; [ebp] = 0x00000000
一级虚拟指令还原成二级虚拟指令 一级虚拟指令还原成二级虚拟指令的方法是利用虚拟堆栈平衡 ,即二级虚拟指令执行后,虚拟栈保持平衡 。具体步骤如下:
从第一条一级虚拟指令执行前开始,记下虚拟栈栈顶指针相对偏移为0(或某一值)
执行一级虚拟指令,根据对应一级虚拟指令的栈指针变化情况,更新虚拟栈栈顶指针相对偏移。
直至虚拟栈栈顶指针的相对偏移重新变为0(或重新变为原值),执行过的一级虚拟指令片段就对应一个二级虚拟指令。
需注意:
连续的虚拟出栈指令和连续的虚拟入栈指令,认为这部分指令是虚拟寄存器环境还原和保存。
虚拟栈平衡不能以一级虚拟入栈指令结束。
虚拟栈平衡不能以一级虚拟运算指令结束。
对于刚才还原出的一级虚拟指令样本,先从最后面分析,往上连续的PushReg指令一般都是虚拟寄存器入栈,用于后续恢复真实环境。那么,切割出一级虚拟指令片段如下:
1 2 3 4 5 6 7 8 9 10 11 PushRegDW R0; R0 = esi
那么根据这个,就需要往前寻找相同数量且连续的PopReg指令,对应一级虚拟指令片段如下:
1 2 3 4 5 6 7 8 9 10 11 PopRegDW R2; R2 = ecx
这里根据VM Entry处的代码进行了虚拟寄存器与真实寄存器之间的映射。
找到了虚拟栈到虚拟寄存器的映射后,就可以从这里开始往下利用虚拟栈平衡划分一级虚拟指令片段了,这里挑出几个片段进行分析。
//此处记虚拟栈指针偏移为0
PushConstDW 0x00403000; -4
LoadDW [[ebp]]; -4 [ebp] = 0x00403000, [[ebp]] = 0xDEADBEEF
PopRegDW R5; 0 [ebp] = 0xDEADBEEF
// 虚拟栈指针偏移重新变为0,以上一级虚拟指令片段对应一个二级虚拟指令
1 2 3 4 5 MOV R5 , [0x00403000 ]
//此处记虚拟栈指针偏移为0
PushConstDW 0x12345678; -4
PushRegDW R5; -8 R5 = 0xDEADBEEF
ADDDW [ebp+4], [ebp+0]; -8 [ebp+4] = 0x12345678, [ebp] = 0xDEADBEEF, [ebp+4]+[ebp] = 0xF0E21567
PopRegDW R7; -4 [ebp] = 0x00000292
PopRegDW R13; 0 [ebp] = 0xF0E21567
// 虚拟栈指针偏移重新变为0,以上一级虚拟指令片段对应一个二级虚拟指令
1 2 3 4 5 R 13 , R 5 , 0x12345678 ; R 13 = R 5 + 0x12345678
//此处记虚拟栈指针偏移为0
PushConstDW 0x12345678; -4
PushRegDW R13; -8 R13 = 0xF0E21567
PushVSPDW; -12 EBP = 0019FF6C
LoadDW [[ebp]]; -12 [ebp] = 0x0019FF6C, [[ebp]] = 0xF0E21567
NAndDW [ebp+4], [ebp+0]; -12 [ebp] = 0xF0E21567, [ebp+4] = 0xF0E21567, ~[ebp+4] & ~[ebp]=0x0F1DEA98
PopRegDW R1; -8 [ebp] = 0x00000202
ADDDW [ebp+4], [ebp+0]; -8 [ebp+4] = 0x12345678, [ebp] = 0x0F1DEA98, [ebp+4]+[ebp] = 0x21524110
PopRegDW R15; -4 [ebp] = 0x00000212
PushVSPDW; -8 EBP = 0019FF70
LoadDW [[ebp]]; -8 [ebp] = 0x0019FF70, [[ebp]] = 0x21524110
NAndDW [ebp+4], [ebp+0]; -8 [ebp] = 0x21524110, [ebp+4] = 0x21524110, ~[ebp+4] & ~[ebp]=0xDEADBEEF
PopRegDW R8; -4 [ebp] = 0x00000282
PopRegDW R1; 0 [ebp] = 0xDEADBEEF
// 虚拟栈指针偏移重新变为0,以上一级虚拟指令片段对应一个二级虚拟指令
1 2 3 4 5 mov R1 , ~(~R13 + 0x12345678 )
1 sub R1, R13, 0x12345678; R13 - 0x12345678
```assemblyR15 ADDDW产生的eflag0xFFFFF7EA & R15) + (~0x00000815 & R8) ~0xFFFFF7EA = 0x00000815 两个eflag合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1 (例如ZF),然后根据这个结果计算目标跳转指令,接着就是执行条件跳转指令。push 指令就平衡了。``` assembly0 push ds :dword_404649push 0 R3 0x765DA981 ebp +4 ], [ebp +0 ]R7 R6
不过后续并没有用到该ADDDW虚拟指令产生的结果和标志位,因此认定为这个片段为混淆指令片段。
最终去除混淆代码以及虚拟寄存器与真实寄存器映射(Pop和Push指令,这个主要是在多个虚拟机中跟踪真实寄存器),还原出的二级虚拟指令如下:
1 2 3 4 mov R5, [0x00403000]; 值为0xDEADBEEF
此时的二级虚拟指令可以说是与源指令一模一样了,所实现的功能并无差异。
四、总结 对于虚拟代码还原,首要是识别处虚拟机的相关数据结构,例如虚拟栈指针、虚拟字节码指针、虚拟字节码表等等,然后人工分析处VM Handler的功能,当然,对于VM Handler的分析,可以借助AI来完成,需要告知虚拟机的相关数据结构,使AI的回答能够更精确。分析完虚拟机的结构以及相关数据结构后,可以尝试提取虚拟机结构的特征,比如VM Dispatcher存在VM Handler Table的使用,然后可以尝试编写代码自动化虚拟机结构的识别。之后借助模拟执行来获取整个代码流的执行情况,根据这个还原出虚拟代码流的一级虚拟指令。
对于一级虚拟指令还原成二级虚拟指令,需要利用到虚拟栈平衡这一特征来划分一级虚拟指令片段,这些片段对应一条或多条二级虚拟指令(复杂的逻辑运算可以尝试简化)。这里我总结了一点规律,如有不对的地方,恳请斧正:
因为基于栈的虚拟机,对于一个完整的二级虚拟指令,首先是将操作数据入栈,然后在栈中进行运算,然后将运算产生的标志位或运算结果出栈,因此对于push操作,可以认定是二级虚拟指令开始的标志,对于pop操作,可以认定是二级虚拟指令结束标志。但仍需要注意的是,运算指令后跟随的第一个出栈指令,是将运算产生的标志位出栈,如果后续没有第二个出栈指令,即运算结果仍然保留在虚拟栈中,则有可能该运算结果仍参与后续的指令的执行,因此还需往后进行虚拟栈平衡分析(test、cmp除外,它们只在意运算产生的标志位)
对于模拟执行得到的本机指令以及还原出的一级虚拟指令中,可能存在无用代码,可以借助变量存活分析(Live-variable analysis) 识别出无用代码并删除,达到简化代码目的。
参考:
如何分析虚拟机系列(1):新手篇VMProtect 1.81 Demo - 吾爱破解 - 52pojie.cn
https://blog.back.engineering/17/05/2021