OLLVM源码解读
基础知识
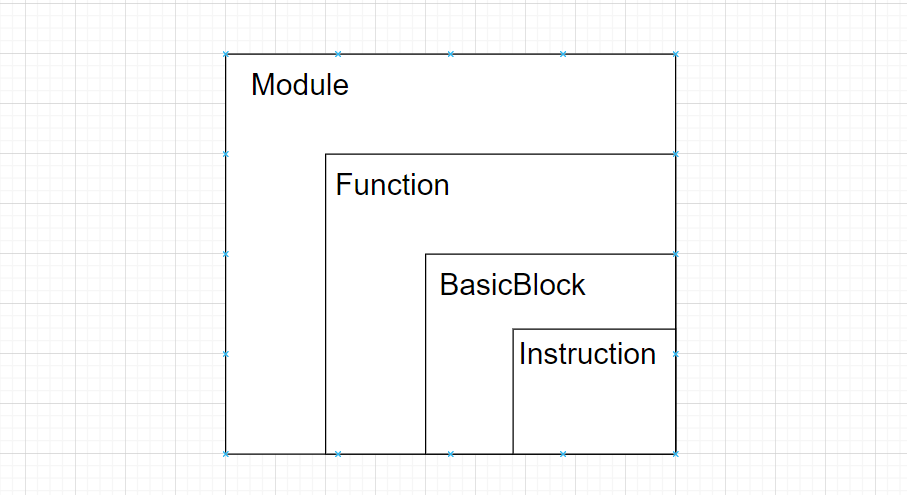
IR(intermediate representation)是前端语言生成的中间代码表示,也是Pass操作的对象,它主要包含四个部分:
- Module:一个源代码文件被编译后生成的IR代码。
- Function:源代码文件中的函数。
- BasicBlock:BasicBlock有且仅有一个入口点和一个出口点。入口点是指BasicBlock的第一个指令,而出口点是指BasicBlock的最后一个指令。BasicBlock中的指令是连续执行的,没有分支或跳转指令直接将控制流传递到BasicBlock内部以外的位置。
- Instruction:指令。
它们之间的关系如下图所示:
Substitution混淆源码解读
runOnFunction函数
1 | |
检查是否能够进行Substitution混淆,混淆的具体操作主要通过调用substitute函数进行的。
substitute函数
1 | |
整个函数的功能主要是根据运算指令中的操作符进行相应的混淆操作,由于同一指令的混淆操作有很多种,因此通过llvm::cryptoutils->get_range获取随机数来指定某种混淆操作。
由于这些运算混淆都大同小异,所以接下来以一个例子来进行Substitution混淆的介绍。
addNeg混淆函数
1 | |
主要是创建一个取反指令和一个整型减法指令来替换原有的指令。
一开始我不理解这些操作具体体现是什么,于是为了探究这些代码对IR进行了什么操作,因此在源码上进行打印调试,打印更改前后的IR。主要修改如下:
1 | |
打印结果如下:
1 | |
从结果上看,Create***等指令创建函数会影响后面的IR代码,即后续代码会进行相应的调整以保证IR代码的正确性,至于其具体过程,本篇博客不进行介绍。replaceAllUsesWith函数并不是真正的将源指令替换或删除,仅仅只是让后续IR代码中对源指令的结果的引用转变成对新指令的结果的引用,也就是说,源指令对后续的操作无任何作用,这样之后的优化应该会删除这种无效IR代码(如果指定了优化等级的话)。
至于其他的运算混淆,通过这个例子可以知其一而知其二。
SplitBasicBlocks源码解读
runOnFunction函数
1 | |
进行一些类似的操作,然后是调用split函数。
split函数
1 | |
这部分主要是遍所有基本块,如果基本块中只含有一条指令或者含有PHI节点,则不进行基本块拆分,同时调整分割次数以防止分割次数大于基本块中的指令数。接下来就是生成分割点,具体操作为对1~size-1的有序vetor打乱顺序,然后对前splitN个进行从小到大的排序,这样做的目的一是随机分割,而是重排序以防止分割不会出错。最后,调整分割点,调用splitBasicBlock进行分割。
先来看看PHI节点是什么。
PHI节点
所有LLVM指令都以静态单一赋值(SSA)形式表示。从本质上讲,这意味着任何变量只能分配给一次。因此就存在如下情况的问题:
1 | |
假设v的值小于10,变量a就会被赋值为2,但是a已经被赋值了一次,由于SSA性质的约束,不能继续给a赋值了。为了解决这一问题,LLVM中引入了PHI节点(PHI Node),用于处理基本块之间的分支和合并。当一个基本块有多个前驱基本块时,PHI节点可以用来表示从不同的前驱基本块中接收的值,这在处理分支和合并的情况下非常有用。
上述代码就会被转换成:
1 | |
if分支里面的赋值被转换成另一个变量,b的赋值也就在两个变量之间选择,通过添加一个PHI Node,让它来决定选择哪个变量赋值给b。
splitBasicBlock
1 | |
以指令I为分割点,所有在分割点之前的指令保留在原来的基本快中,分割点处的指令以及之后的指令保留到新的基本块中,并且在原来的基本块后面增加跳转到新的基本块的br指令。之后是修正新基本块的后继基本块(同样也是分割之前的基本块的后继基本块)中的PHINode,具体操作为替换PHINode的前驱基本块(即分割之前的基本块)为新的基本块。
Flattening源码解读
flatten函数
runOnFunction函数没啥好看的,直接看重点:flatten函数,将该函数分为以下几块进行讲解。(这一部分的理解可以参考Obfuscator-llvm源码分析 - 知乎 (zhihu.com)中的CFG图)
首先弄了一个随机数,这个不需要着重分析。
1
2
3
4// SCRAMBLER
char scrambling_key[16];
llvm::cryptoutils->get_bytes(scrambling_key, 16);
// END OF SCRAMBLER然后是创建
LowerSwitchPass并执行该Pass。1
2
3// Lower switch
FunctionPass *lower = createLowerSwitchPass();
lower->runOnFunction(*f);LowerSwitchPass的作用是将函数中的switch指令转换成一系列连续的if-then指令。具体的操作我没仔细看,也不打算深究。接下来将函数
f的所有基本块存放一份到向量origBB中,同时检查基本块中的终止指令,如果终止指令是Invoke指令,则对整个函数f不进行平坦化混淆。如果函数f的基本块数量<1也不进行平坦化混淆。最后是将函数f的第一个基本块从向量origBB中删除。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18// Save all original BB
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
BasicBlock *tmp = &*i;
origBB.push_back(tmp);
BasicBlock *bb = &*i;
if (isa<InvokeInst>(bb->getTerminator())) {
return false;
}
}
// Nothing to flatten
if (origBB.size() <= 1) {
return false;
}
// Remove first BB
origBB.erase(origBB.begin());接下来引入3个问题。
第一个问题:什么是Terminator?
在
LLVM的IR中,每个基本块必须以Terminator指令结尾,它标志着基本块的结束,用于控制接下来代码流进入到哪一个基本块中。Terminator指令,它可以是分支指令(如BranchInst)、返回指令(如ReturnInst)或者抛出异常的指令(如InvokeInst)等。第二个问题:什么是InvokeInst?
InvokeInst是一种特殊的调用指令,用于调用有异常处理的函数。与普通的CallInst不同,如果函数调用期间抛出异常,则控制流会转移到指定的异常处理代码中,而不是继续执行后续的指令。InvokeInst指令,这个指令有两个后继,但是一个是正常的基本块处,另一个是跳转到unwind相关的逻辑中(异常处理),这个unwind基本块的开头必须为LandingPadInst,且只能通过InvokeInst指令来到达。第三个问题:为什么基本块中含有InvokeInst就对所在函数不进行平坦化处理?
由于
unwind基本块只能通过InvokeInst指令来到达。所以当LandingPadInst被插入到SwitchInst中去的时候,由于不是通过InvokeInst到达的,所以会报错。然而对所在函数不进行平坦化,感觉应该不太妥,对于这部分的优化可以参考OLLVM控制流平坦化的改进 - 知乎 (zhihu.com)。
对第一个基本块进行单独处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 获取函数f中的第一个基本块
Function::iterator tmp = f->begin(); //++tmp;
BasicBlock *insert = &*tmp;
// 如果函数f中的第一个基本块的末尾为分支指令
BranchInst *br = NULL;
if (isa<BranchInst>(insert->getTerminator())) {
br = cast<BranchInst>(insert->getTerminator());
}
// 最后一条指令是条件分支指令 或者 有多个后继基本块
if ((br != NULL && br->isConditional()) || insert->getTerminator()->getNumSuccessors() > 1) {
//获取基本块中最后一个指令作为分割点(end()获取的是最后一个指令的下一个节点)
BasicBlock::iterator i = insert->end();
--i;
//如果基本块中的指令 > 1,那么分割点为倒数第二条指令
if (insert->size() > 1) {
--i;
}
//以指令i为分割点分割基本块,并返回新的基本块,然后将新的基本块插入到origBB中的第一个基本块之前
BasicBlock *tmpBB = insert->splitBasicBlock(i, "first");
origBB.insert(origBB.begin(), tmpBB);
}
// 删除函数f中的第一个基本块(也就是分割之后的旧的基本块)的终止指令(末尾)
insert->getTerminator()->eraseFromParent();具体而言,如果该基本块的后续基本块有多个,则进行基本块拆分,将拆分出的新的基本块插入到
origBB中的第一个基本块之前。基本块拆分是为了保证第一个基本块只有一个后继基本块,以便后续跳转到loopEntry基本块中。最后删除第一个基本块中的末尾指令(删除到后继基本块的跳转指令,后续会添加到loopEntry基本块的跳转)。构建一个循环
switch-case的框架,建立基本块之间的跳转连接。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29// Create switch variable and set as it
switchVar = new AllocaInst(Type::getInt32Ty(f->getContext()), 0, "switchVar", insert);
new StoreInst(ConstantInt::get(Type::getInt32Ty(f->getContext()), llvm::cryptoutils->scramble32(0, scrambling_key)), switchVar, insert);
// Create main loop
loopEntry = BasicBlock::Create(f->getContext(), "loopEntry", f, insert);
loopEnd = BasicBlock::Create(f->getContext(), "loopEnd", f, insert);
load = new LoadInst(switchVar, "switchVar", loopEntry);
// Move first BB on top
insert->moveBefore(loopEntry);
// first BB jump to loopEntry
BranchInst::Create(loopEntry, insert);
// loopEnd jump to loopEntry
BranchInst::Create(loopEntry, loopEnd);
// create swDefault BB
BasicBlock *swDefault = BasicBlock::Create(f->getContext(), "switchDefault", f, loopEnd);
// swDefault jump to loopEnd
BranchInst::Create(loopEnd, swDefault);
// Create switch instruction itself and set condition
switchI = SwitchInst::Create(&*f->begin(), swDefault, 0, loopEntry);
switchI->setCondition(load);
// Remove branch jump from 1st BB and make a jump to the while
f->begin()->getTerminator()->eraseFromParent();
BranchInst::Create(loopEntry, &*f->begin());具体来说是,在函数
f第一个基本块(拆分后)的末尾创建switchVar路由变量并赋予随机值。接着创建loopEntry、loopEnd、swDefault基本块。然后在loopEntry基本块的末尾加载switchVar路由变量,之后又在loopEntry基本块的末尾创建SwitchInst指令,设置默认分支为swDefault基本块,设置case分支数量为0,最后设置SwitchInst指令的路由变量为load指令加载的switchVar。其余的BranchInst则是建立基本块之间的跳转。此时
CFG图如下: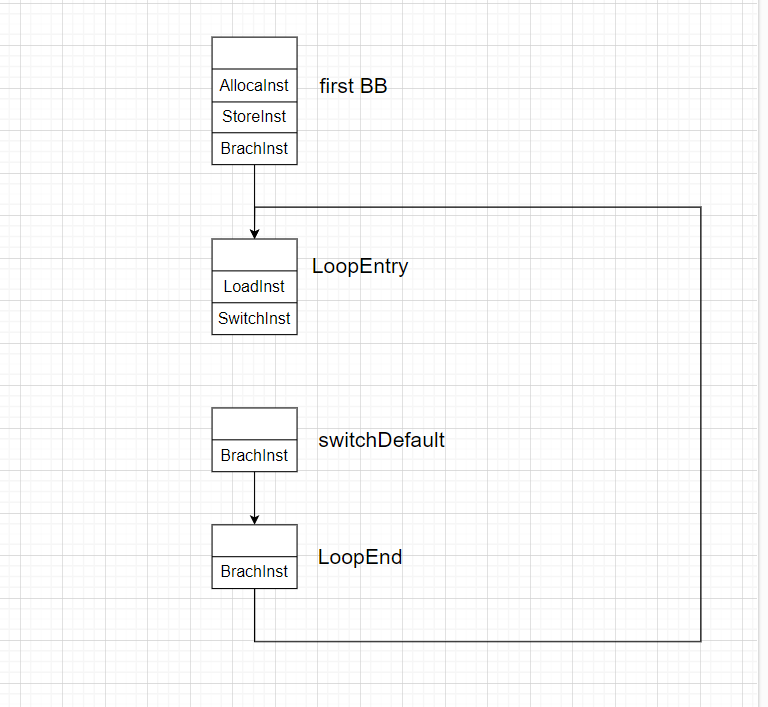
将
origBB中所有的基本块按照case索引值加入到switch-case分支中。1
2
3
4
5
6
7
8
9
10
11
12
13// 遍历origBB的所有基本块
for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end(); ++b) {
BasicBlock *i = *b;
ConstantInt *numCase = NULL;
// 将基本块移动到loopEnd之前(位置意义上的,而非代码逻辑上的)
i->moveBefore(loopEnd);
// 生成numCase,并将基本块i加入到对应索引值的case分支处
numCase = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)));
switchI->addCase(numCase, i);
}看完整个
Flattening源码后,我还在想源码中并没有通过设置switchVar来确保代码流在第一个基本块能够正确进入到原本的后续基本块中。后面我反复阅读源码后才发现,其实它们之间的跳转关系在这里就确定了!注意看!!!初始
switchVar的值为:1
llvm::cryptoutils->scramble32(0, scrambling_key))origBB中的第一个基本块的case索引值为:1
llvm::cryptoutils->scramble32(switchI->getNumCases(), scrambling_key)此时
switchI->getNumCases()的值就是0,这么一来,初始switchVar的值恰好指向下一个正确的基本块。此时
CFG图如下: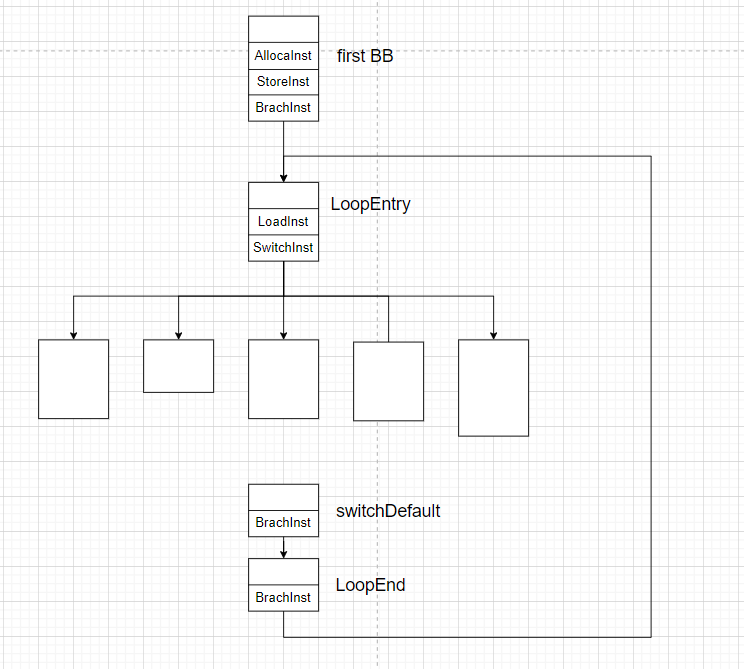
根据基本块的后继基本块数量,决定是否在基本块中添加更新
switchVar(路由变量)的指令,使代码流能够进入正确的基本块中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62//遍历origBB中的每个基本块
for (vector<BasicBlock *>::iterator b = origBB.begin(); b != origBB.end(); ++b) {
BasicBlock *i = *b;
ConstantInt *numCase = NULL;
// return或exit基本块,不做处理
if (i->getTerminator()->getNumSuccessors() == 0) {
continue;
}
// 有一个后继基本块的基本块(以非条件跳转结尾的基本块)
if (i->getTerminator()->getNumSuccessors() == 1) {
//获取后继基本块,同时删除最后一条指令(跳转指令)
BasicBlock *succ = i->getTerminator()->getSuccessor(0);
i->getTerminator()->eraseFromParent();
//找到后继基本块所在的case位置(是个索引值)
numCase = switchI->findCaseDest(succ);
//如果后继基本块是default基本块,则创建一个case索引值
//不对呀,之前不是将所有的基本块都加入到case分支中嘛,怎么还会有numCase==Null的
//就算是有后继基本块不在case中的,那也应该将它加入到case中,而这里没有,仅仅只是生成numCase
if (numCase == NULL) {
numCase = cast<ConstantInt>( ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(->getNumCases() - 1, scrambling_key)));
}
//创建store指令,存储numCase到switchVar中,指令插入到基本块i中的最后面,这一步即更新switchVar的值
new StoreInst(numCase, load->getPointerOperand(), i);
BranchInst::Create(loopEnd, i);
continue;
}
// 有两个后继基本块的基本块(以条件跳转结尾的基本块)
if (i->getTerminator()->getNumSuccessors() == 2) {
//获取这两个后继基本块
ConstantInt *numCaseTrue = switchI->findCaseDest(i->getTerminator()->getSuccessor(0));
ConstantInt *numCaseFalse = switchI->findCaseDest(i->getTerminator()->getSuccessor(1));
// Check if next case == default case (switchDefault)
if (numCaseTrue == NULL) {
numCaseTrue = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(switchI->getNumCases() - 1, scrambling_key)));
}
if (numCaseFalse == NULL) {
numCaseFalse = cast<ConstantInt>(ConstantInt::get(switchI->getCondition()->getType(),
llvm::cryptoutils->scramble32(switchI->getNumCases() - 1, scrambling_key)));
}
// 获取基本块中的条件跳转指令,根据这个指令,创建Select指令,第一个参数是条件变量,
// 第二个是条件为真的结果,第三个是条件为假的结果,并将指令插入到基本块i的条件跳转指令之前
BranchInst *br = cast<BranchInst>(i->getTerminator());
SelectInst *sel = SelectInst::Create(br->getCondition(), numCaseTrue, numCaseFalse, "", i->getTerminator());
//删除基本块i的条件跳转指令
i->getTerminator()->eraseFromParent();
// 更新switchVar的值为sel,插入到基本块i中的末尾
new StoreInst(sel, load->getPointerOperand(), i);
BranchInst::Create(loopEnd, i);
continue;
}
}将基本块分为三种类型进行处理:
- 没有后续基本块的基本块:这种基本块通常以
retn或者call exit结尾,统一称为Ret BB。对于这类基本块,不做处理。 - 有一个后续基本块的基本块:这种基本块以非条件跳转指令结尾。对于这类基本块,删除其与后续基本块的跳转关系,转而变成通过
switch-case结构跳转,即通过store指令更新switchVar路由变量的值为后继基本块所在case的索引值,最后增加跳转到loopEnd基本块的指令。 - 有两个后续基本块的基本块:这种基本块以条件跳转指令结尾。对于这类基本块,删除其与后续基本块的跳转关系,转而变成通过
switch-case结构跳转,即创建select指令,并通过store指令将select指令的结果作为新的switchVar路由变量的值,最后增加跳转到loopEnd基本块的指令。
此时
CFG图如下: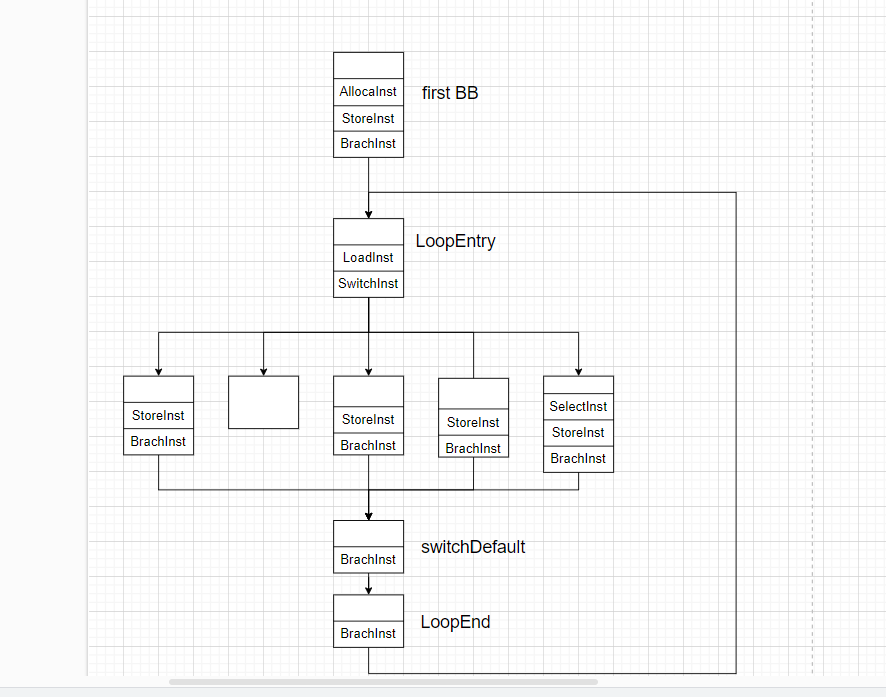
- 没有后续基本块的基本块:这种基本块通常以
优化函数中的堆栈分配
1
fixStack(f);对应具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38void fixStack(Function *f) {
// Try to remove phi node and demote reg to stack
std::vector<PHINode *> tmpPhi;
std::vector<Instruction *> tmpReg;
BasicBlock *bbEntry = &*f->begin();
do {
tmpPhi.clear();
tmpReg.clear();
//遍历基本块
for (Function::iterator i = f->begin(); i != f->end(); ++i) {
//遍历基本块中的指令
for (BasicBlock::iterator j = i->begin(); j != i->end(); ++j) {
//如果该指令是PHI节点,则加入到tmpPhi中
if (isa<PHINode>(j)) {
PHINode *phi = cast<PHINode>(j);
tmpPhi.push_back(phi);
continue;
}
//指令不是位于入口基本块的alloca指令且该指令含有逃逸变量,加入到tmpReg中
if (!(isa<AllocaInst>(j) && j->getParent() == bbEntry) &&
(valueEscapes(&*j) || j->isUsedOutsideOfBlock(&*i))) {
tmpReg.push_back(&*j);
continue;
}
}
}
//对逃逸变量进行降级处理,从虚拟寄存器变量降级到堆栈上的局部变量
for (unsigned int i = 0; i != tmpReg.size(); ++i) {
DemoteRegToStack(*tmpReg.at(i), f->begin()->getTerminator());
}
//对phinode进行降级处理,从phinode降级为堆栈上的局部变量
for (unsigned int i = 0; i != tmpPhi.size(); ++i) {
DemotePHIToStack(tmpPhi.at(i), f->begin()->getTerminator());
}
} while (tmpReg.size() != 0 || tmpPhi.size() != 0);
}这个函数处理了两种类型的指令:
PHI 指令
PHI 指令我们前面介绍过。因为PHI指令是基于前驱基本块的指令,前驱基本块被打乱了,PHI指令会出现错误,因此需要对PHI指令进行修复。
含有逃逸变量的指令
逃逸变量指的是在当前基本块中被定义,在其他的基本块中被引用了的变量。这类逃逸变量在编译(LLVM IR->目标平台机器代码)时会出现分不清定义和引用顺序的问题,因此也需要进行修复。
DemoteRegToStack函数用于将存储指令结果值的虚拟寄存器替换为堆栈上的局部变量。具体而言,首先创建Alloca指令,插入到函数的入口基本块中,然后如果该指令是Invoke指令,则进行基本块分割,然后对于使用逃逸变量的基本块,采用Load指令从堆栈中加载变量的值,最后创建Store将逃逸变量的值存储到堆栈中。DemotePHIToStack函数用于将存储PHI节点的结果值的虚拟寄存器替换为堆栈上的局部变量。具体而言是创建Alloca指令,插入到函数的入口基本块中,对于PHI节点的每一个前驱基本块,插入一个Store指令,将前驱基本块传递过来的值存储到堆栈中。之后在PHI节点所在的位置插入一个Load指令,将之前存储在堆栈中的值加载出来。简而言之,
DemotexxxToStack函数就是使用Alloca、Store、Load指令来代替这些需要待修复的指令。
BogusControlFlow源码解读
runOnFunction函数
从runOnFunction函数入手看:
1 | |
这部分主要是调用bogus函数进行虚假控制流混淆,然后调用doF函数替换在bogus函数中创建的永真条件跳转指令。我们先来看bogus函数然后再看doF函数。
bogus函数
1 | |
外面一层while循环是循环虚假控制流混淆次数,对于每次混淆,先将函数的所有基本块加入到basicBlocks中,然后内层while循环遍历每个基本块,生成对应的混淆概率,如果满足预设混淆概率,就调用addBogusFlow函数进行混淆。
addBogusFlow函数
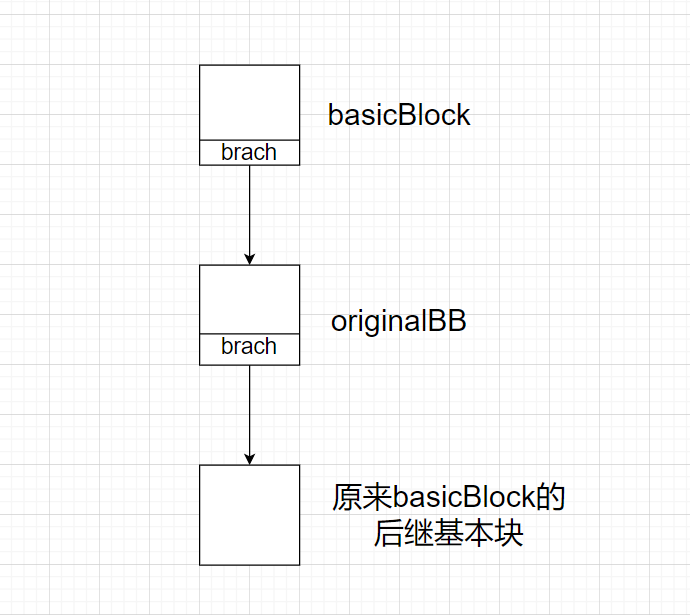
首先是获取分割点,然后对要混淆的基本块进行基本块分割,新的基本块的名字为originalBB。
1 | |
此时,CFG的情况如下:
然后是通过createAlteredBasicBlock函数(这个函数主要是根据传入的基本块fork出新的基本块,然后进行修正和垃圾指令填充)创建一个名为alteredBB基本块,删除alteredBB和basicBlock末尾的分支指令。
1 | |
此时,CFG的情况如下:

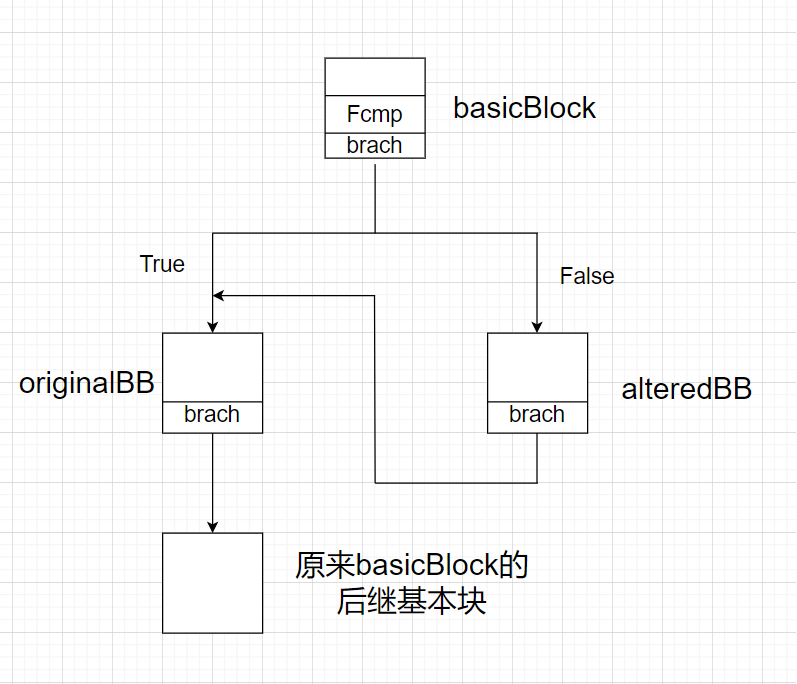
接下来是创建了一个永真的Fcmp指令(因为1.0 == 1.0),并以该指令为条件码创建条件跳转指令,都插入到basicBlock的末尾,如果为True,跳转到originalBB,否则跳转到alteredBB。之后创建从alteredBB跳转到originalBB的跳转指令。
1 | |
此时,CFG的情况如下:
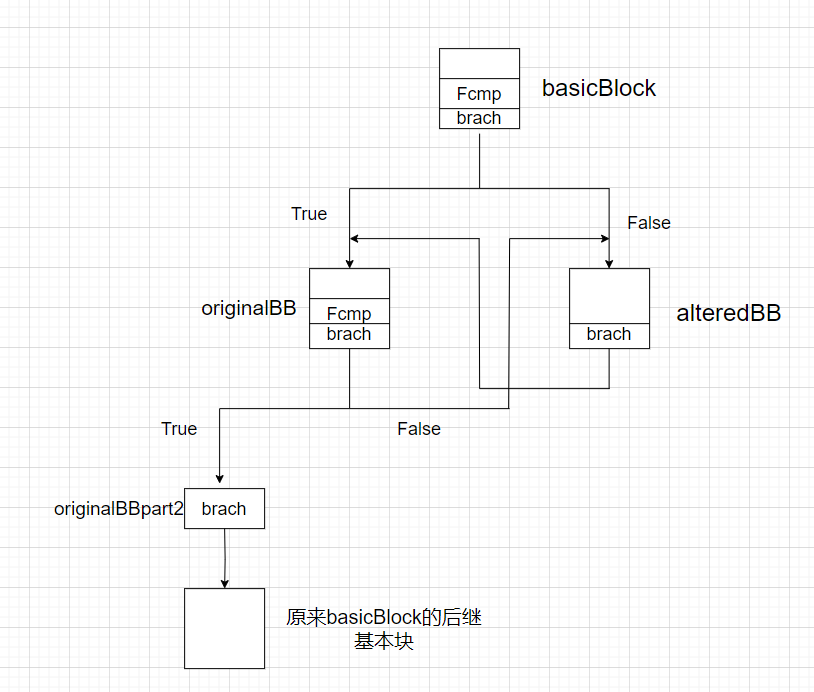
最后,以originalBB的末尾跳转指令分割originalBB,新的基本块名为originalBBpart2,删除originalBB末尾的跳转指令(跳转到originalBBpart2),然后创建一个永真的Fcmp指令,并以该指令为条件码创建条件跳转指令,都插入到originalBB的末尾,如果为True,跳转到originalBBpart2,否则跳转到alteredBB。
1 | |
此时,CFG的情况如下:
createAlteredBasicBlock函数
首先调用CloneBasicBlock函数从basicBlock中克隆alteredBB,这个basicBlock是待混淆的基本块通过splitBasicBlock函数分割出来的新的基本块。
1 | |
然后是修复alteredBB,主要是重映射指令中的操作数和PHINode的前驱基本块。
1 | |
最后是往alteredBB中添加垃圾指令。
1 | |
doF函数
首先是创建两个全局变量x,y,初始值为0。
1 | |
然后是遍历指令,将永真条件跳转指令加入到toEdit中,以及将对应的永真比较指令加入到toDelete中。
1 | |
接下来是遍历toEdit中存放的永真条件跳转指令,创建条件码x*(x-1)%2 == 0 || y < 10,以该条件码创建条件跳转分支,然后删除之前的永真条件跳转指令。最后删除toDelete中存放的永真比较指令。
1 | |
参考:
LLVM Concepts — llvmpy 0.9.0 documentation(phi node)
Obfuscator-llvm源码分析 - 知乎 (zhihu.com)(有详细的CFG图)
[原创]基于LLVM Pass实现控制流平坦化-软件逆向-看雪-安全社区|安全招聘|kanxue.com(flatten混淆)
OLLVM控制流平坦化的改进 - 知乎 (zhihu.com)(flatten混淆)
[原创]OLLVM控制流平坦化之fixStack解析-软件逆向-看雪-安全社区|安全招聘|kanxue.com(fixStack函数)
https://bbs.kanxue.com/thread-266201.htm(BogusControlFlow混淆)