阅读笔记 —— 《ObfuscatorDynamic-LLVM》
一些基本概念
动态分析技术
- 调试(debugging)
- 内存分析(memory profiling)
- 模糊测试(fuzzing)
- 动态符号执行(dynamic symbolic execution,简称DSE)
动态符号执行
使用自动化方法,执行引擎使用输入的符号表示来求解和引导执行沿着两个分支进行,它会将分支条件作为约束条件,然后使用SMT solver求解所需的输入。它有3个致命缺点:
路径爆炸
分支呈指数级增长。这会导致求解超时、爆内存。
路径发散
这个发生在DSE引擎无法从程序代码精确计算路径约束时。这是由自我修改的代码方案引起的,该方案迫使引擎猜测要执行的指令的正确值。
复杂约束
给 SMT 求解器的约束太难求解了。这通常是通过使用加密哈希函数来实现的。
软件保护技术
两个评价软件保护技术的指标:
- potency:用于描述攻破保护技术所需要的资源。
- resilience:用于描述攻破保护技术的困难程度。
软件保护技术的要求:
任何应用到软件包上的保护技术都不应产生高昂的成本,它不应增加代码/二进制文件的大小,也不应显著增加运行时开销。
软件加密
软件加密面临的四个挑战:
- bulk/on demand:加载程序时是否应该立即解密所有代码,还是在需要执行时按需解密代码?
- fine/course granularity:一次应该解密多少?应该一次解密一个基本块、函数还是一个模块?
- key-as-data/key-as-code:解密密钥应该作为数据存储在程序中,还是应该从代码派生?
- keep-in-the-clear/re-encrypt:解密的代码应该保持明文形式,还是应该在执行后重新加密?
嗯,怎么感觉跟软件加壳面临的问题一样!?
软件混淆
混淆的基本原理是转换代码,使其在功能上等效,但更复杂。复杂性可以以数据结构的形式出现,也可以以控制流的形式出现。
混淆不能改变程序的可观测行为,它只能使程序的运行逻辑更加复杂。
混淆的基本架构:
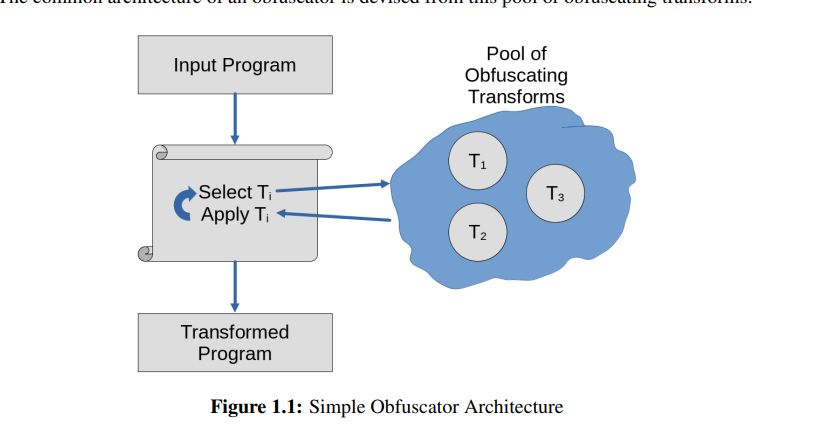
混淆分为两大类:
静态混淆
通过注入垃圾指令来完成,这些指令会稀释程序的真实逻辑。这种混淆已经在许多不同级别的程序代码上完成,从高级语言源代码到汇编代码。这种混淆在编译阶段完成。
动态混淆
在程序代码运行时会更改程序代码,以使程序保持在恒定的动态状态。程序在编译时通过混淆来注入自我修改的代码,然后在运行时定期触发该代码以更改程序的过去/未来指令/数据。动态混淆的范围从简单的指令覆盖到运行时的加密/解密。动态混淆可以有效的防止动态分析。
混淆技术
- 指令替换(Instruction Substitution/Arithmetic Encoding)
- 字符串加密(String Encoding)
- 虚假代码插入(Irrelevant/Bogus Code Insertion)
- 不透明谓词和构造(Opaque Predicates and Constructs)
- 控制流扁平化(Control Flow Flattening)
- 自修改代码(Self-Modifying Code)
- 虚拟化(Virtualization)
Self-Modifying Code
自修改代码,作用是在程序运行时修改程序自身代码。最简单的一种是使用虚假指令替换,在执行虚假指令之前,使用更新例程来恢复原始的正确指令。如果在错误的时间删除了更新例程,则程序行为在功能上不再正确。
这种保护背后的想法是:真正的指令只在一小段时间内可见,因此逆向工程师需要捕获该窗口期间的行为。
自修改代码作为一种动态混淆变换,大多数形式的静态分析在分析它时都是无用的。反编译器不知道指令是如何或何时被覆盖的。
Virtualization
虚拟化可以使每个副本与其他副本完全不同,因此可以严重限制逆向工程师对所有副本的攻击能力。虚拟化使程序能够在运行时进行更改。
虚拟化采用一个函数,并将其转换为解释器。该函数使用虚拟指令集架构 (ISA) 执行,该架构是为每个函数随机生成的。虚拟指令集架构的随机性是软件副本之间最大的多样性。当转换后的函数被执行时,虚拟指令集架构被转换为计算系统的真实底层指令集架构,然后被执行。虚拟化也可以嵌套,其中函数被虚拟化两次,并具有两个不同的虚拟 ISA。静态分析方法在这种转换下几乎毫无用处,但动态分析仍然可以与之抗衡。虚拟化是成本最高的混淆之一,而且在嵌套时,会导致无法忍受的运行时开销。但是,并非程序的每个功能都需要虚拟化,因此混淆器可以通过仅虚拟化少数功能来限制成本。
Range Divider Obfuscation Transform
Range Divider混淆尝试通过引入额外分支,这些分支条件依赖于输入,因此这些分支能够使得DSE引擎持续不断的求解,从而触发路径爆炸问题。要想使得分支条件取决于输入,我们可以欺骗DSE引擎,让它认为这个分支是跟输入相关的,但实际上并不是。(不透明谓词的引入并不会影响DSE求解,因为没有输入依赖性,DSE 引擎可以立即将其作为死代码消除)
Range Divider Obfuscation Transform的一个例子:

本论文提出的争对动态攻击的新保护
引入了两种新混淆来抵抗DSE攻击:
- FOR obfuscation
- WRITE obfuscation
FOR obfuscation利用了DSE的分支爆炸问题,引入指数增长的分支给DSE。
WRITE obfuscation利用了DSE的路径发散问题,引入自修改的汇编代码,该代码在运行时覆盖指令。
ObfuscationDynamic-LLVM实现
ObfuscationDynamic-LLVM,简称OD-LLVM,具备OLLVM的功能,并额外实现如下图红框所示功能:

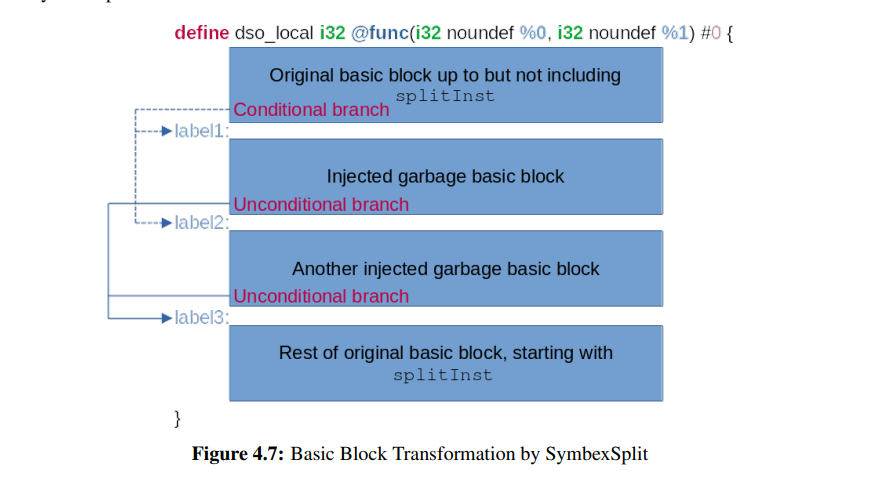
SymbexSplit Obfuscation Transform
SPLIT变换注入了一个if语句,其中谓词依赖于相关变量。if 语句可以带有或不带有 else 子句,这些语句正文中的内容可以是垃圾指令,也可以是原始指令的不同混淆版本。在实现 SymbexSplit 时,选择将垃圾指令注入 if/else 语句的正文中,这样可以最大限度地降低将原始程序指令更改为非功能等效指令的风险。
SymbexSplit Obfuscation Transform的实现:
- 选择一个随机指令用于将基本块一分为二,并称这个指令为 splitInst。
- 分配内存给垃圾变量并初始化,这些垃圾变量用于if语句正文中。
- 使用 splitInst 作为拆分点将基本块分成两半。
- 创建两个基本块来操作垃圾变量。
- 向拆分基本块的上半部分插入带有输入依赖谓词的条件分支,这些分支将跳转到其他一个垃圾基本块中。
- 向每个垃圾基本块中添加无条件分支,这些分支会跳转到拆分基本块的下半部分。
示例图:
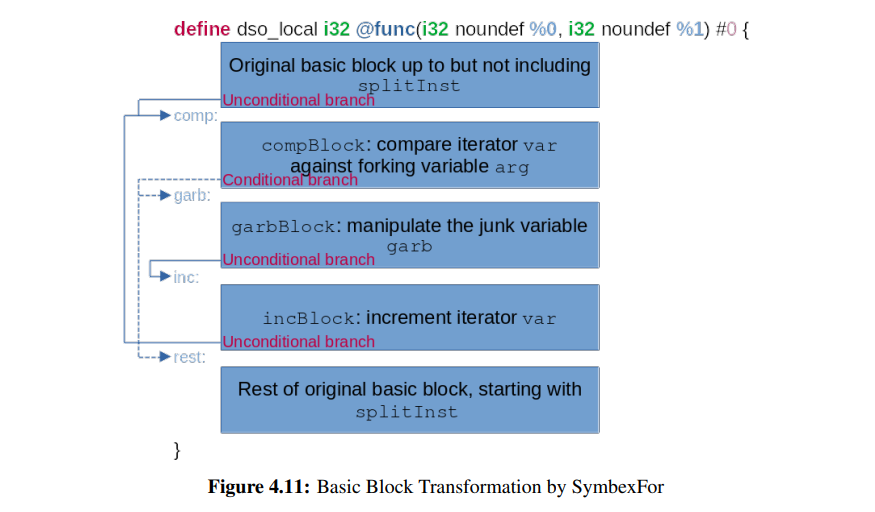
SymbexFor Obfuscation Transform
FOR 转换注入一个 for 语句,其中循环停止谓词依赖于相关变量,for 循环的主体充满了垃圾指令。
SymbexFor Obfuscation Transform的实现如下:
- 选择一个随机指令用于将基本块一分为二,并称这个指令为 splitInst。
- 分配内存给垃圾变量并初始化,这些垃圾变量将用在 for 循环主体中。
- 使用 splitInst 作为拆分点将基本块分成两半。
- 将 for 循环构造拆分为3个基本块:
- compBlock:for 循环的相关变量依赖谓词。
- garbBlock:for 循环的垃圾变量操作体。
- incBlock:for 循环的迭代变量递增语句。
- 向拆分基本快的上半部分插入无条件分支,用于跳转到compBlock。
- 向compBlock中插入条件分支,这些分支要么跳转到garbBlock,要么跳转到拆分基本快的下半部分。
- 向garbBlock中插入无条件分支,用于跳转到incBlock。
- 向incBlock中插入无条件分支,用于跳转到compBlock。
示例图: