阅读笔记 —— 《Software Obfuscation on a Theoretical Basis and Its Implementation》
概述
软件混淆是一种有前途的方法,用于在不受信任的环境中保护软件的知识产权和秘密信息。不幸的是,以前的软件混淆技术存在一个主要缺点:它们没有理论基础,因此不清楚其有效性。为此,我们在本文中提出了新的软件混淆技术。这些技术基于**软件程序过程间分析(intraprocedural analysis)的难度。我们的混淆技术的本质在于解决一个新的复杂性问题,即在存在函数指针数组的情况下,精确确定函数指针指向的地址。**我们证明了这个问题是NP难的,这一事实为我们的混淆技术提供了理论基础。此外,我们已经实现了一个原型工具,根据我们提出的技术对C程序进行混淆,并在本文中描述了该实现和讨论实验结果。
函数指针对于软件混淆非常有用,原因如下:
- 函数指针的存在显著破坏静态分析,尤其是过程间分析。这是因为通过函数指针进行的过程调用使得在编译时确定控制流变得困难。因此,大多数传统的静态分析技术无法应对函数指针,通常会忽略它们。
- 我们的混淆技术可以提供理论基础,因为其本质是一个新的复杂性问题,简而言之,就是在存在函数指针数组的情况下,精确确定函数指针指向的地址。本文证明了这个问题是NP难的。
除了使用函数指针外,本文还提出了两种新的混淆技术来阻碍过程间分析。它们增加了程序中unrealizable路径的数量。因此,它们极大地降低了静态分析的精确性,使得混淆后的程序更难理解。
防篡改软件
实现软件防篡改的主要方法可以分为以下三类:
远程执行
程序的一部分保存在一个安全的可信服务器上,用户远程执行该程序。缺点是服务器压力大,网络通信导致性能差。
硬件防护
利用专用硬件来实现软件防篡改。缺点是成本贵。(当然也有用专们开挂的硬件DMA)
混淆
将程序转换成难以理解和非法篡改的形式。软件混淆被认为是在不受信任的环境中保护软件知识产权和秘密信息的最可行的方法。
函数指针混淆
函数指针混淆程序分为三个阶段:
- 函数分解(Decomposition of procedures)
- 函数指针的使用(Use of function pointers)
- 函数指针数组的引入( Introduction of arrays of function pointers)
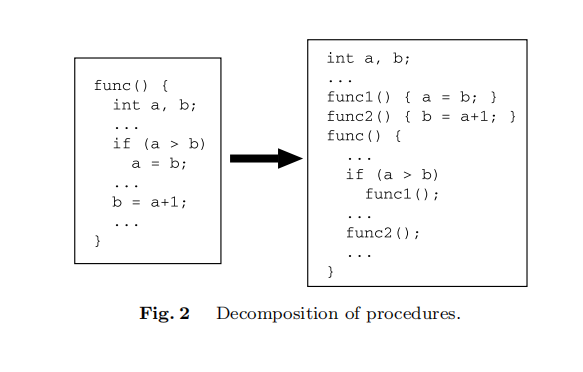
函数分解
随机选择一个函数,将其分解为较小的函数,并用这些分解后的函数重构原始函数,同时保持原始语义。函数分解的基本原则是随机选择一些连续的语句,并将它们组织成一个新的函数。
具体步骤如下:
- 选择过程:首先随机选择一个没有全局分支的函数(例如,没有函数调用、goto语句、return语句等)。这样的函数可以包含if语句或for语句,因为它们是函数内的局部分支。
- 分解语句:然后在该函数中进一步选择一系列语句,并将它们组成一个新的函数。新创建的函数必须反映其在原始函数中的功能。在上述简单情况下,可以通过让这些函数共享从原始函数中的局部变量提升为全局变量来完成。
上述步骤在程序中的多个函数中随机重复。在此阶段,我们可能会在程序中插入虚假函数,使得控制流图和调用图的节点和边的数量变得更多,导致程序的函数间分析变得更加困难。
函数指针的使用
函数之间的调用强制通过函数指针调用,例子如下图所示。

额外增加了不透明谓词混淆,使得在静态分析中很难确定函数指针 fp 所指向的函数地址。
函数指针数组的引入
随机将函数地址存储到数组中,并准备表达式通过一些(直接或间接)函数调用来计算每个索引。
例子如下图所示。图中提供了一个函数指针数组A和一个帮助计算A索引的函数func0,该函数始终返回偶数,因此原始程序的语义得以保持。

对fp的赋值取决于通过fp(先前的值)和指针数组A的相应元素的函数调用。它们的组合显著地削弱了静态分析的效果。
增加unrealizable路径的混淆
两种混淆方法
- 合并函数调用( Mergence of procedure calls into one call)
- 添加冗余的返回语句(Additions of redundant return-statements)
以上方法都是为了增加程序的unrealizable路径的数量。
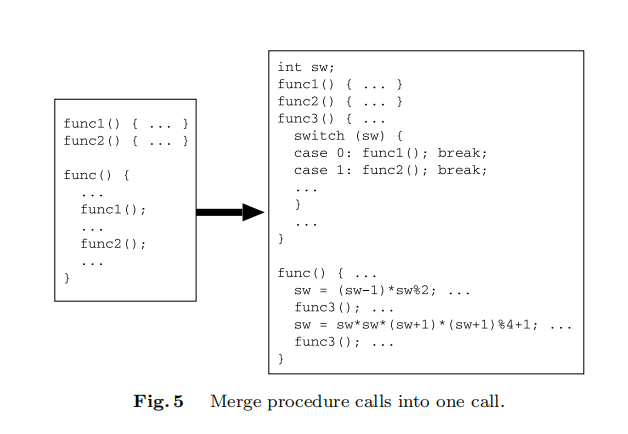
合并函数调用
具体步骤如下:
- 选择过程调用:随机选择一个函数中的多个函数调用 $f_{i_1}(…),…,f_{i_n}(…)$,这些函数调用具有相同的返回值类型。
- 创建新过程:创建一个新函数 $f_{n+1}$,将 $f_{i_1}(…),…,f_{i_n}(…)$ 包含在这个新函数中。
- 引入位置变量:引入一个路由变量 $sw$,用来记住在原始过程 $func$ 中 $f_{i_1}(…),…,f_{i_n}(…)$ 被调用的位置。
- 替换过程调用:将 $func$ 中的 $f_{i_1}(…),…,f_{i_n}(…)$ 替换为对新过程 $f_{n+1}$ 的调用。
- 传递参数:如果 $f_{i_1}(…),…,f_{i_n}(…)$ 需要参数,则通过$f_{n+1}$ 的参数传递这些参数。
具体例子如下图所示。
该例子中的函数调用图如下所示。
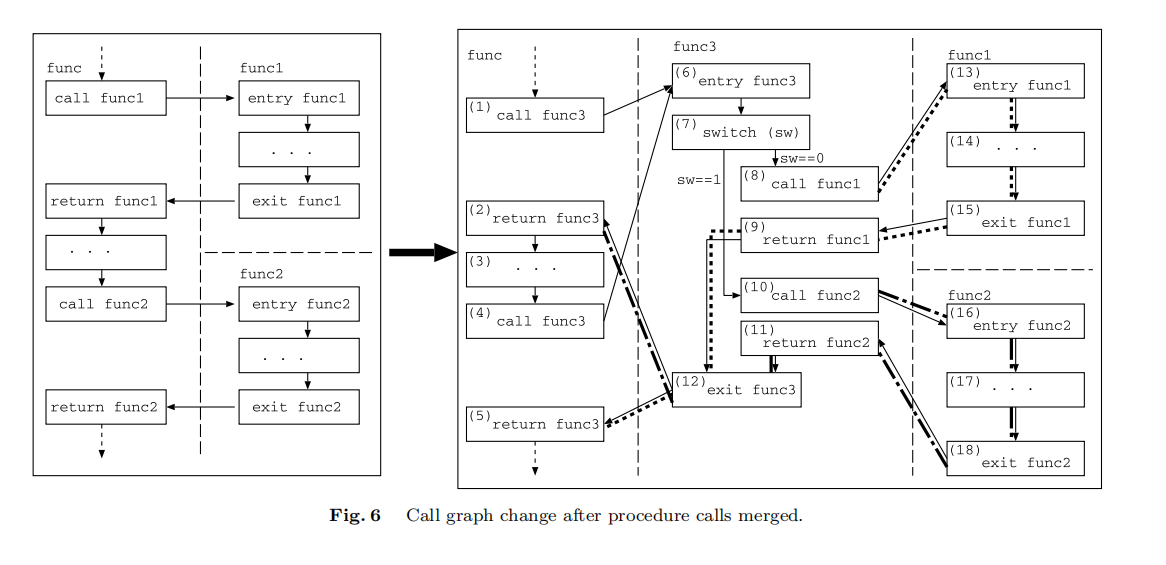 存在两条unrealizable路径:
存在两条unrealizable路径:
- ···→ [(15) exit func1] → [(9) return func1] → [(12) exit func3] → [(5) return func3] → ···
- ···→ [(18) exit func2] → [(11) return func2] → [(12) exit func3] → [(2) return func3] → ···
工具框架
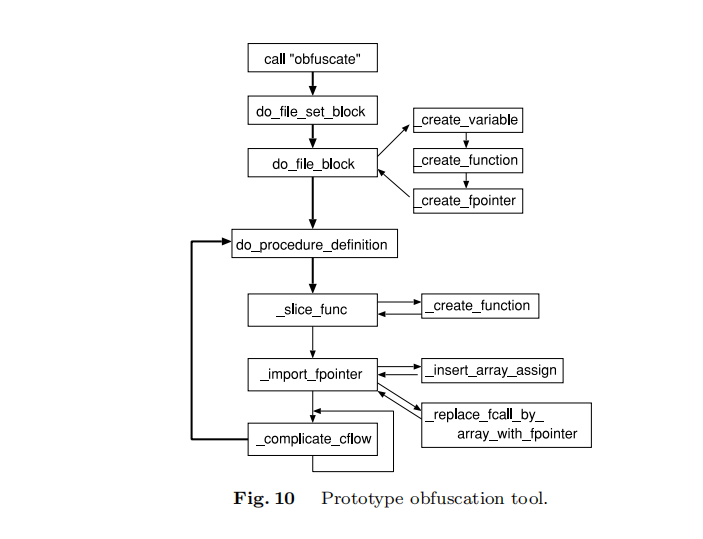
工具工作流程:
首先,读取目标程序并借助
SUIF2将其转换为IR表示。然后,依次执行
ObfuscatePass类的两个方法(do_file_set_block和do_file_block)以进行初始化。do_file_set_block初始化全局数据结构。do_file_block调用create_variable、create_function和create_fpointer方法,以生成辅助变量、虚拟函数、函数指针和函数指针数组。
之后可能会多次调用
do_procedure_definition方法对目标程序进行混淆。do_procedure_definition方法通过调用slice_func(函数分解)、import_fpointer(引入函数指针和数组)和complicate_cflow(复杂化调用图的结构),将随机选择的过程转换为混淆的过程。