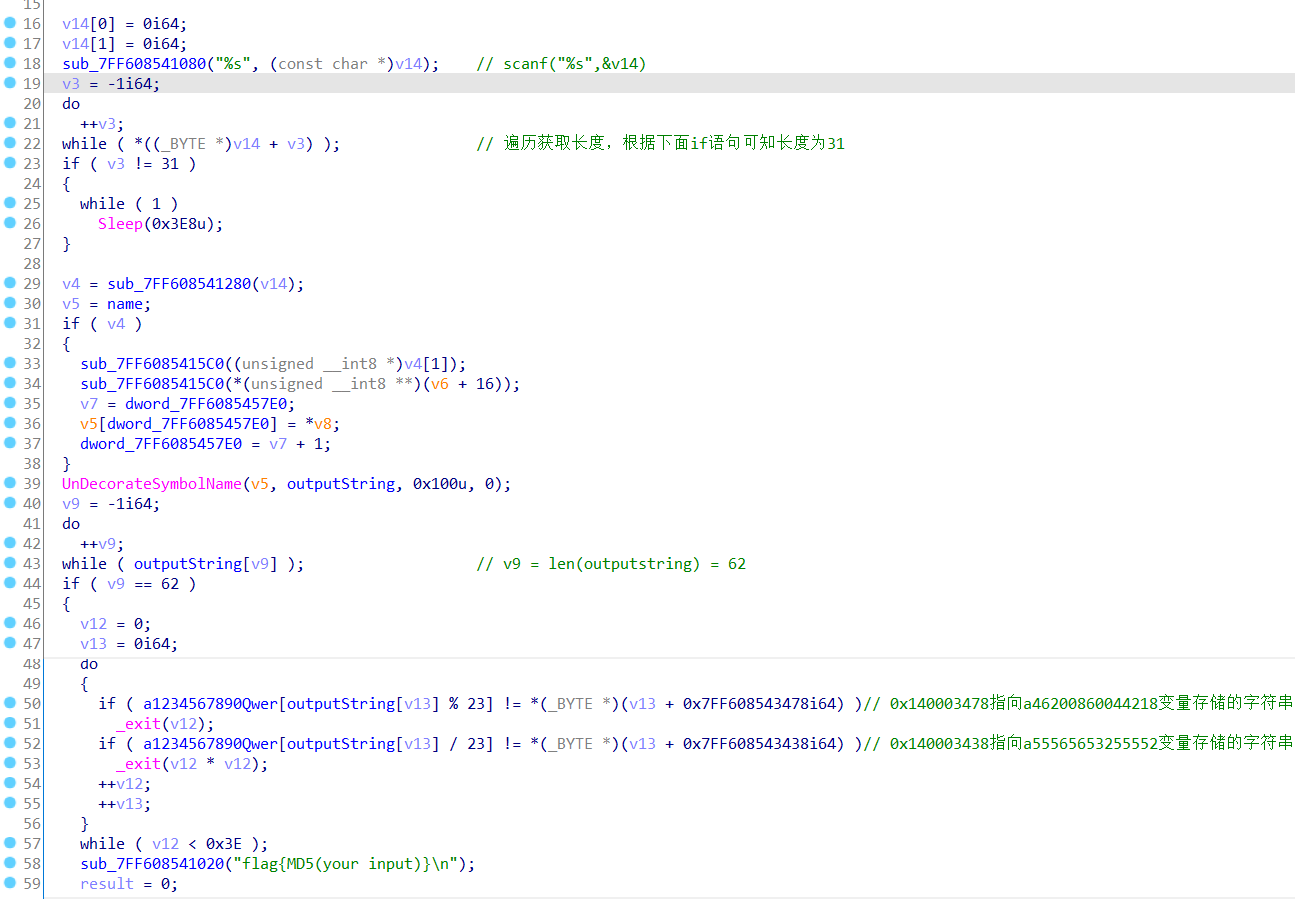
部分分析如图所示。第29行的sub_xxxx是个复杂的函数,尝试分析过。第33~34行的这两个函数是二叉树的后序遍历
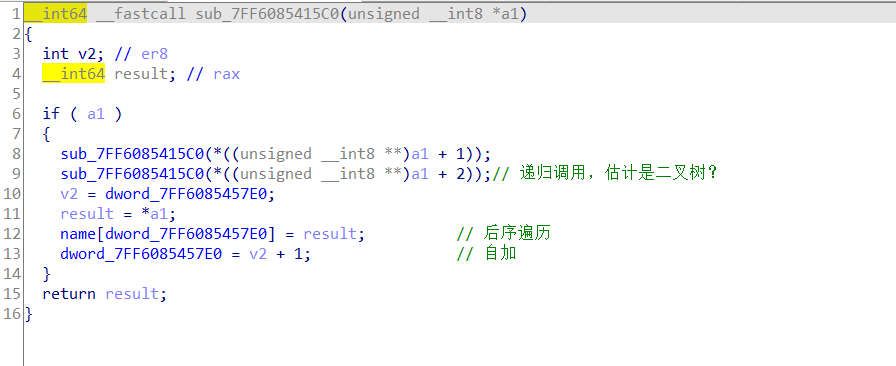
且遍历的结果存储到name中。
之后比较关键的函数是UnDecorateSymbolName函数,这个函数在官方文档上有介绍,但不是很详细,于是问了问chatgpt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 好的,让我们以 C++ 语言为例来说明 `unDecorateSymbolName` 函数的使用。
在 C++ 中,函数名称经过装饰后会包含参数类型、返回类型等信息。例如,`void foo(int)` 函数在装饰后可能会变成 `_Z3fooi`。而 `unDecorateSymbolName` 函数可以将这样的装饰后的符号名称还原成可读的形式。
以下是一个简单的例子:
```cpp
#include <iostream>
#include <windows.h>
#include <dbghelp.h>
int main() {
const char* decorated = "_Z3fooi";
DWORD length = 256;
char buffer[256];
if (UnDecorateSymbolName(decorated, buffer, length, UNDNAME_COMPLETE)) {
std::cout << "Original symbol name: " << buffer << std::endl;
} else {
std::cout << "Failed to undecorate symbol name." << std::endl;
}
return 0;
}
```
在上述代码中,我们使用了 Windows 平台下的 `UnDecorateSymbolName` 函数,并传入装饰后的符号名称 `_Z3fooi`。通过调用该函数,我们可以得到还原后的符号名称 `void __cdecl foo(int)`。最终输出结果为:
```
Original symbol name: void __cdecl foo(int)
```
这个例子演示了如何使用 `unDecorateSymbolName` 函数将装饰后的符号名称还原成可读形式,以便更好地理解函数的定义。请注意,实际的函数调用可能会因编程语言和开发环境而有所不同,需要根据具体情况进行相应的调整。
|
根据这个例子,可以知道unDecorateSymbolName 函数的功能是将装饰后的符号名称还原成可读形式,这里的outputString就是可读形式的函数名定义,我们要求的name就是该函数定义修饰后的结果。
那问题来了,函数修饰的规则是什么?
函数符号(函数的名字修饰):在编译阶段生成的字符串,来指明函数的定义或原型。
参考:C/C++函数符号生成规则(函数名的修饰);C++ 函数重载_Scl_Diligent的博客-CSDN博客
根据上述规则可恢复name。
回到代码中,接下来比较关键的是50、52行,v13后面加的数据其实就是某些字符串的起始地址,所以根据这两行代码可以恢复outputString。
1
2
3
4
5
6
7
8
9
10
11
12
|
str1 = '55565653255552225565565555243466334653663544426565555525555222'
str2 = '(_@4620!08!6_0*0442!@186%%0@3=66!!974*3234=&0^3&1@=&0908!6_0*&'
str3 = '1234567890-=!@#$%^&*()_+qwertyuiop[]QWERTYUIOP{}asdfghjkl;\x27ASDFGHJKL:"ZXCVBNM<>?zxcvbnm,./'
outputstring = ''
slen = 62
for v13 in range(slen):
data = str3.index(str1[v13])*23 + str3.index(str2[v13])
outputstring += chr(data)
print(outputstring)
|
求出outputString之后,根据函数名修饰规则手动恢复出name
1
| ?My_Aut0_PWN@R0Pxx@@AAEPADPAE@Z
|
接下来就是逆二叉树后序遍历了。因为不知道二叉树结构而且只知道一种遍历结果,是无法恢复的。所以我们尝试IDA动调,随便输入符合条件的字符串,构造出一个对照表,然后替换内容得到源字符串(假设为Src)。在IDA动调过程中,是可以发现第29行的sub_xxx函数对我们的输入是没有影响的,那么我们求出的源字符串Src就是输入。
1
2
3
4
5
6
7
8
9
10
| name = '?My_Aut0_PWN@R0Pxx@@AAEPADPAE@Z'
table1 = 'abcdefghijklmnopqrstuvwxyzABCDE'
table2 = 'pqhrsidtujvwkebxylzAmfBCnDEogca'
plain = ''
for i in range(len(name)):
pos = table2.index(table1[i])
plain += name[pos]
print(md5(plain.encode()).hexdigest())
|